1 | var flatten = function(arr) { |
React合成事件机制
Js执行上下文和作用域链以及this
Js执行流程:
编译阶段
变量提升:
是指在JavaScript代码执行过程中,JavaScript引擎把变量的声明部分和函数的声明部分提升到代码开头的“行为”。变量被提升后,会给变量设置默认值,这个默认值就是我们熟悉的undefined。
执行部分的代码
经过编译后,生成两部分内容:执行上下文和可执行代码
执行上下文包括变量环境,词法环境,外部引用Outer(指向外部的执行上下文)和this,一般包括三种:全局执行上下文,函数执行上下文(调用函数,函数内代码被编译,创建函数上下文,函数执行结束,上下文销毁),eval(使用eval函数时,eval的代码会被编译,并创建执行上下文)
执行上下文会被js引擎压入调用栈中,执行完毕后,会把执行上下文弹出栈
执行阶段
Js引擎开始执行可执行代码,按照顺序一行行执行,当出现相同的变量和函数,会保存到执行上下文的变量环境中,一段代码如果定义了两个相同名字的函数,那么最终生效的是最后一个函数,而
作用域和作用域链以及词法作用域
作用域指在程序定义变量的区域,该位置决定了变量的生命周期,作用域就是变量与函数的可访问范围,即作用域控制着变量和函数的可见性和生命周期
ES6之前只有全局作用域和函数作用域
- 全局作用域中的对象在代码中的任何地方都能访问,其生命周期伴随着页面的生命周期。
- 函数作用域就是在函数内部定义的变量或者函数,并且定义的变量或者函数只能在函数内部被访问。函数执行结束之后,函数内部定义的变量会被销毁。
ES6后多了一个块级作用域,let和const会创建块级作用域
变量提升造成的危害:
1.变量容易在不被察觉的情况在被覆盖
2.本应该被销毁的变量没被销毁:
1 | function foo(){ |
由于变量提升,变量i在创建执行上下文阶段被提升,当for循环结束,变量i没有被销毁
ES6解决变量提升带来的缺陷:
使用let和const支持块级作用域,块作用域中的变量会被放到执行上下文中的词法环境中,而不是变量环境,因此块级作用域中的变量不会出现变量提升的现象
词法作用域:
指作用域是由代码中函数声明的位置决定的,所以词法作用域是静态的作用域,通过它能够预测代码在执行过程中如何查找标识符
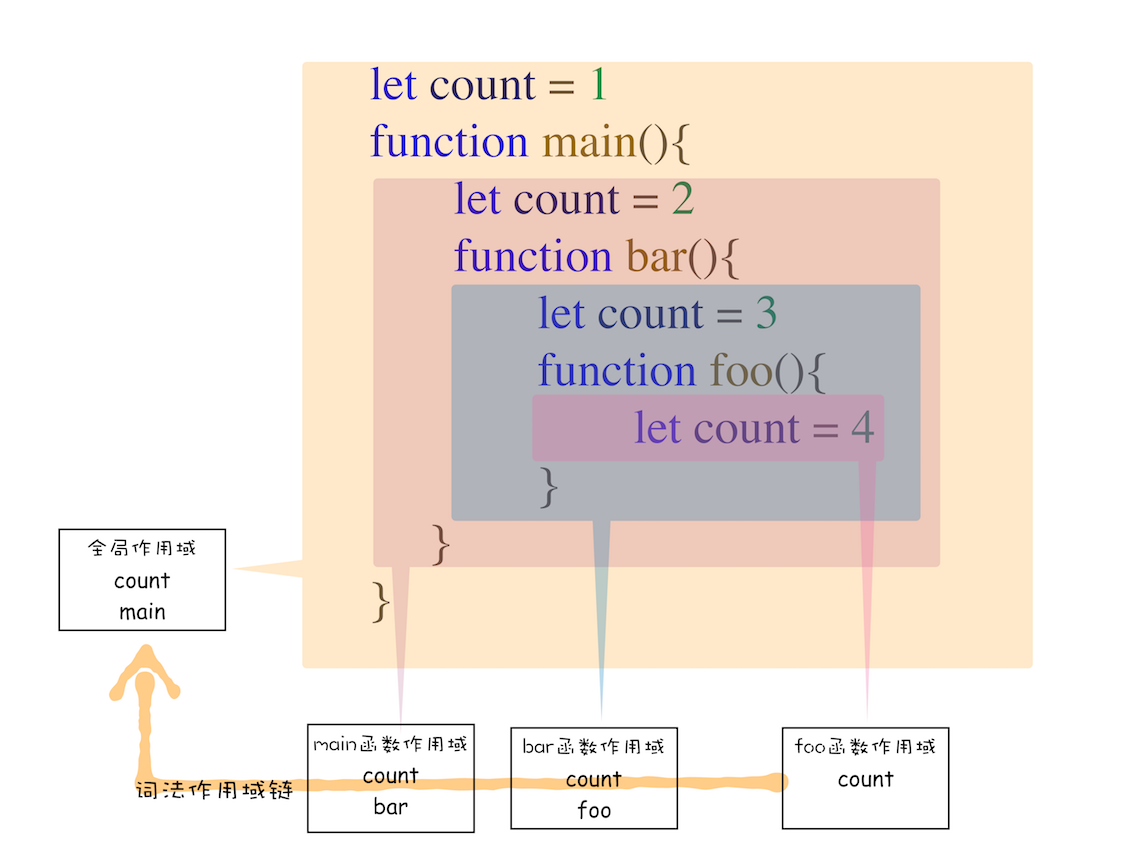
词法作用域由代码声明时的位置决定,所以整个词法作用域链顺序:foo函数作用域->bar函数作用域->main函数作用域->全局作用域
例子:
1 | function bar() { |
它的执行上下文栈如下:
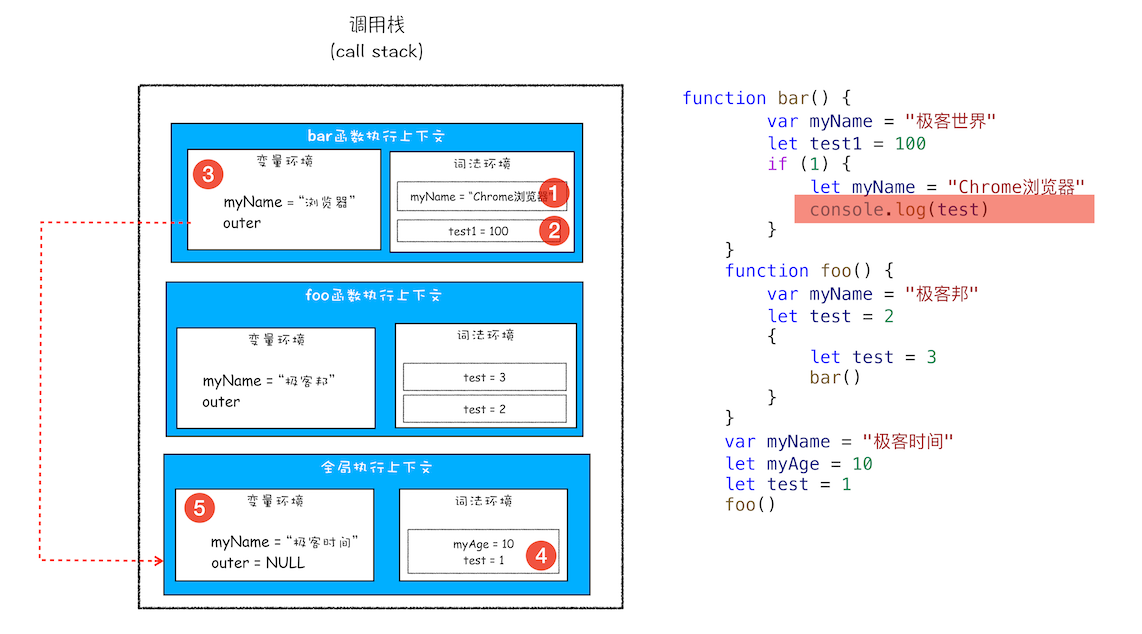
先在执行上下文中的词法环境中查找->变量环境->外部作用域,最后在全局执行上下文的词法环境中找到test
从执行上下文角度看闭包:
1 | function foo() { |

根据词法作用域的规则,内部函数getName和setName总是可以访问到外部函数foo中的变量,左移当InnerBar对象返回给全局变量bar后,虽然foo函数已经执行结束,但是getName和setName函数依然可以使用foo函数中的变量myName和test1,当foo函数执行完成后,整个调用栈状态如下:

闭包定义:在JavaScript中,根据词法作用域的规则,内部函数总是可以访问其外部函数中声明的变量,当通过调用一个外部函数返回一个内部函数后,即使该外部函数已经执行结束,但是内部函数引用外部函数的变量依然保存在内存中,我们把这些变量的集合称为闭包。
闭包回收
如果引用闭包的函数是全局变量,那么闭包会一直存在直到页面关闭;但如果这个闭包以后不再使用的话,就会造成内存泄漏。
如果引用闭包的函数是个局部变量,等函数销毁后,在下次 JavaScript 引擎执行垃圾回收时,判断闭包这块内容如果已经不再被使用了,那么 JavaScript 引擎的垃圾回收器就会回收这块内存。
所以在使用闭包的时候,你要尽量注意一个原则:如果该闭包会一直使用,那么它可以作为全局变量而存在;但如果使用频率不高,而且占用内存又比较大的话,那就尽量让它成为一个局部变量。
在执行上下文的视角讲this
作用域链和this是两套不同的系统,
this 是和执行上下文绑定的,也就是说每个执行上下文中都有一个 this。执行上下文主要分为三种——全局执行上下文、函数执行上下文和 eval 执行上下文,所以对应的 this 也只有这三种——全局执行上下文中的 this、函数中的 this 和 eval 中的 this。
全局执行上下文中的 this
全局执行上下文中的 this 是指向 window 对象的。这也是 this 和作用域链的唯一交点,作用域链的最底端包含了 window 对象,全局执行上下文中的 this 也是指向 window 对象
#函数执行上下文中的 this
1. 通过函数的 call 方法设置
2. 通过对象调用方法设置
3. 通过构造函数中设置
this 的设计缺陷以及应对方案
1. 嵌套函数中的 this 不会从外层函数中继承
我认为这是一个严重的设计错误,并影响了后来的很多开发者,让他们“前赴后继”迷失在该错误中。我们还是结合下面这样一段代码来分析下:
1 | var myObj = { |
解决:
1.在外层函数中用一个变量self保存this
1 | var myObj = { |
2 内部函数使用箭头函数的形式
1 | var myObj = { |
箭头函数不会创建自身的执行上下文,因此箭头函数中的this取决于它的作用域链中的上一个执行上下文中的this
2. 普通函数中的 this 默认指向全局对象 window
上面我们已经介绍过了,在默认情况下调用一个函数,其执行上下文中的 this 是默认指向全局对象 window 的。
不过这个设计也是一种缺陷,因为在实际工作中,我们并不希望函数执行上下文中的 this 默认指向全局对象,因为这样会打破数据的边界,造成一些误操作。如果要让函数执行上下文中的 this 指向某个对象,最好的方式是通过 call 方法来显示调用。
这个问题可以通过设置 JavaScript 的“严格模式”来解决。在严格模式下,默认执行一个函数,其函数的执行上下文中的 this 值是 undefined,这就解决上面的问题了
async-await原理
Generator和协程
生成器函数的具体使用方式:
在生成器函数内部执行一段代码,如果遇到 yield 关键字,那么 JavaScript 引擎将返回关键字后面的内容给外部,并暂停该函数的执行。
外部函数可以通过 next 方法恢复函数的执行
Generator返回的是一个协程,协程是一种比线程更轻量级的存在,你可以把协程看出是跑在线程上的任务,一个线程上可以存在多个协程,但是在线程上同时只能执行一个协程,比如当前执行的是A协程,要启动B协程,那么协程就需要把主线程的控制权交给B协程。如果从A协程启动B协程,把A协程称为B协程的父协程
一个进程拥有多个线程,一个线程也可以拥有多个协程,协程不是由操作系统内核管理,而完全是由程序控制(也就是用户态执行),好处就是性能得到了提升,不会像线程切换那样消耗资源
1 | function* genDemo() { |

协程四点规则:
- 调用生成器函数genDemo创建一个写成gen,创建后,gen协程并没有立即执行
- 要让gen协程执行,需要通过调用gen.next
- 当协程正在执行时,可以通过yield关键字来暂停gen协程的执行,并返回主信息给父协程
- 如果协程在执行期间,遇到return关键字,那么js引擎会结束当前协程,并将return后面的内容返回给父协程
父协程有自己的调用栈,gen 协程时也有自己的调用栈,当 gen 协程通过 yield 把控制权交给父协程时,V8 是如何切换到父协程的调用栈?当父协程通过 gen.next 恢复 gen 协程时,又是如何切换 gen 协程的调用栈?
要搞清楚上面的问题,你需要关注以下两点内容。
第一点:gen 协程和父协程是在主线程上交互执行的,并不是并发执行的,它们之前的切换是通过 yield 和 gen.next 来配合完成的。
第二点:当在 gen 协程中调用了 yield 方法时,JavaScript 引擎会保存 gen 协程当前的调用栈信息,并恢复父协程的调用栈信息。同样,当在父协程中执行 gen.next 时,JavaScript 引擎会保存父协程的调用栈信息,并恢复 gen 协程的调用栈信息。
使用Promise和generator:
1 | //foo 函数 |
在foo函数里实现了用同步方式实现异步操作,foo函数外部代码:
- let gen=foo()创建gen协程
- 父协程中通过执行gen.next把主线程控制权交给gen协程
- gen协程获取到主线程控制权,就调用fetch函数创建一个Promise对象reponse1,然后通过yield暂停gen协程的执行,将response1返回给父协程
- 父协程恢复执行后,调用reponse1.then方法等待结果
- 等通过fetch发起的请求完成后,会调用then中回调函数,then中的回调函数拿到结果后,通过调用gen.next放弃主线程控制权
把执行生成器的代码封装成一个函数,并把这个执行生成器代码的函数称为执行器
1 | function* foo() { |
async/await
async是一个通过异步执行并隐式返回Promise作为结果的函数
调用async的foo函数返回一个Promise对象,
1 | async function foo() { |
foo函数被async标记,当进入该函数时,js引擎会保存当前调用栈信息,当执行到await(100),会默认创建一个Promise对象。
1 | let promise_ = new Promise((resolve,reject){ |
在这个promise__对象创建过程中,executor函数调用resolve函数,js引擎会将该任务提交给微任务,然后js引擎会暂停当前协程执行,将主线程的控制权交给父协程执行,同时将promise__对象返回给父协程,主线程的控制权已经交给父协程,这时候父协程要做的事就是调用promise_.then监控 promise状态的改变。继续执行父协程的流程,执行console.log(3),父协程执行结束后,在结束之前,会进入微任务检查点,执行微任务队列,微任务队列有resolve(100),触发promise_.then的回调函数
1 | promise_.then((value)=>{ |
Promise告别回调函数
异步编程的问题:
1.代码逻辑不连续
1 | // 执行状态 |
上述代码包含五个回调,导致代码逻辑不连贯,不线性,这就是异步回调影响我们的编程方式。
2.回调地狱
1 | XFetch(makeRequest('https://time.geekbang.org/?category'), |
嵌套调用,下面的任务依赖上个任务的请求结果,并在上个任务的回调函数内部执行新的业务逻辑,这样嵌套层次多了以后,代码可读性变差
任务不确定性,执行每个任务有两种可能的结果(成功或者失败),所以体现在代码中就需要对每个任务的执行结果做两次判断,这种对每个任务都要进行一次额外的错误处理方式,明显增加了代码的混乱程度。
解决两个问题:
- 消灭嵌套调用
- 合并多个任务的错误处理
Promise如何消灭嵌套调用和多次错误处理
产生嵌套函数的主要原因就是在发起任务请求时会带上回调函数,这样当任务处理结束后,下个任务就只能在回调函数中处理
1.Promise实现回调函数延时绑定。在代码上体现就是先创建Promise对象x1,通过Promise的构造函数executor来执行业务逻辑,创建好Promise对象x1后,再使用x1.then设置回调函数:
1 | // 创建 Promise 对象 x1,并在 executor 函数中执行业务逻辑 |
2.将回调函数onResolve的返回值穿透到最外层,因为我们会根据onResolve函数的传入值来决定创建什么类型的Promise任务,创建好的Promise对象需要返回到最外层,这样就可以摆脱嵌套循环。
1 | // 创建 Promise 对象 x1,并在 executor 函数中执行业务逻辑 |
处理异常:
1 | function executor(resolve, reject) { |
这段代码四个Promise对象,无论哪个对象抛出异常,都可以通过最后一个对象p4.catch捕获异常,通过这种方式可以将所有Promise对象的错误合并到一个函数来处理,这样就解决了每个任务需要单独处理异常的问题。Promise对象的错误具有“冒泡”性质,会一直向后传递,直到被onReject函数处理或catch语句捕获为止。具备这样的“冒泡”特性后,就不需要在每个Promise对象中单独捕获异常。
Promise与微任务
由于Promise采用回调函数延迟绑定技术,所以在执行resolve函数时,回调函数还没有绑定,那么只能推迟回调函数的执行
1 | function Promise(executor){ |
执行这段代码:
1 | function executor(resolve,reject){ |
代码报错是由于Promise的延迟绑定导致的,在调用onResolve_时,Promise.then还没执行,所以会报onResolve_ is not a function错误
因此,改造Promise的resolve方法,让resolve延迟调用onResolve_
1 | function Promise(executor){ |
用定时器推迟onResolve执行,用定时器效率低,因此用微任务
参考链接:
nextTick原理
为什么有nextTick?
因为vue采用的异步更新策略,当检测到数据发生变化时不会立即更新DOM,而是开启一个任务队列,并缓存在同一个事件循环中发送的所有变更,当直接操作DOM改变数据时,DOM不会立刻更新,会等到异步队列清空,也就是下一个事件循环开始时执行更新时才会进行必要的DOM更新,这种做法带来的好处就是可以将多次数据更新合并成一次,减少操作DOM的次数,如果不采用这种方法,假设数据改变100次就要去更新100次DOM,而频繁的DOM更新是很耗性能的;
nextTick作用
nextTick 接收一个回调函数作为参数,并将这个回调函数延迟到DOM更新后才执行;
使用场景:想要操作 基于最新数据生成的DOM 时,就将这个操作放在 nextTick 的回调中
nextTick实现原理
将传入的回调函数包装成异步任务,异步任务又分为微任务和宏任务,为了尽快执行选择微任务,nextTick 提供了四种异步方法 Promise.then、MutationObserver、setImmediate、setTimeout(fn,0)
源码解读:
1 | import { noop } from 'shared/util' |
fiber架构原理
Fiber起源
React15之前,Reconciler采用递归创建虚拟DOM,递归过程不能中断,如果组件树的层级很深,递归会占用线程很多时间,造成卡顿
React16将递归的无法中断的更新重构为异步的可中断更新,由于曾经用于递归的虚拟DOM数据结构已经无法满足需要,全新的Fiber诞生
Fiber含义
1.作为架构,React15的Reconciler采用递归的方式执行,数据保存在递归调用栈中,所以被称为stack Reconciler,React 16 的Reconciler基于Fiber节点实现,被称为Fiber Reconciler
2.作为静态数据结构来说,每个Fiber节点对应于一个React element**,保存了该组件的类型**(函数组件/类组件/原生组件…),对应的DOM结点信息
3.对于动态的工作单元来说,每个Fiber结点保存了本次更新中该组件改变的状态,要执行的工作(需要被删除/被插入页面/被更新)
Fiber结构:
1 | function FiberNode ( |
作为架构来说
每个Fiber节点有个对应的React element,多个Fiber节点如何连接成树?
1 | //指向父级Fiber结点 |
作为静态的数据结构
保存了相关组件的信息
1 | // Fiber对应组件的类型 Function/Class/Host... |
作为动态的工作单元
1 | // 保存本次更新造成的状态改变相关信息 |
保存优先级调度的相关信息
1 | // 调度优先级相关 |
Fiber架构的工作原理:
双缓存:
在内存中构建并直接替换的技术叫做双缓存
React使用双缓存来完成Fiber树的构建和替换——对应着DOM树的创建和更新
双缓存Fiber树
React中最多同时存在两棵Fiber树,当前屏幕显示内容对应的Fiber树称为current Fiber树,正在内存中构建的Fiber树称为workInProgress Fiber树,current Fiber树中的Fiber节点称为current fiber,workInProgress Fiber树中的Fiber节点被称为workInProgress fiber,它们通过alternate属性连接
1 | currentFiber.alternate === workInProgressFiber; |
React应用的根节点通过使用current指针在不同的Fiber树的rootFiber间切换来完成current Fiber树之间的切换
即当workInProgress Fiber树构建完成交给Renderer渲染在页面后,应用根结点的current指针指向workInProgress Fiber树,此时workInProgress Fiber树就变为current Fiber树
总结:
Reconciler工作的阶段称为render阶段,因为该阶段会调用组件的render方法
Renderer工作的阶段称为commit阶段,commit阶段会把renderer阶段提交的信息渲染到页面
render与commit阶段统称为work,即React在工作中,相对应的,如果任务正在Scheduler内调度,不属于work.
手写一个loader
loader是导出为一个函数的node模块,该函数在loader转换资源时调用,给定函数将调用loader API,并通过this上下文访问
最简单的loader源码:
1 | module.exports = function(source){ |
获得Loader的options:
1 | const loaderUtils = require("loader-utils") |
返回其他结果
有些场景下还需要返回除了内容外的东西,比如source Map,以方便调试源码
1 | module.exports = function(source){ |
this.callback是webpack给loader注入的api,以方便loader和webpack之间的通信,this.callback详细用法:
1 | this.callback( |
同步和异步
loader有同步和异步,同步loader的转换流程都是同步的,转换完成后再返回结果,但在有些场景下转换是异步的,例如一些网络请求
1 | module.exports = function(source) { |
本地测试自定义loader:
1.在rule对象使用path.resolve指定一个本地文件
1 | const path = require('path') |
匹配多个loader可以使用resolveLoader.modules配置,webpack将会从这些目录中搜索这些loaders,例如你的项目中有一个/loaders本地目录:
webpack.config.js:
1 | module.exports = { |
编写一个插件
webpack插件由以下组成:
一个javaScript命名函数或者JavaScript类
由插件函数的prototype上定义的一个apply方法
指定一个绑定到webpack自身的事件钩子
处理webpack内部实例的特定数据
功能完成后调用webpack提供的回调
1 | // 一个 JavaScript 类 |
webpack通过plugin机制让其更加灵活,以适应各种应用场景,在webpack运行的生命周期中会广播出许多事件,plugin可以监听这些事件,在合适的时机通过webpack提供的api改变输出结果
Compiler和Compilation
插件开发中最重要的两个资源就是compiler和compilation对象,理解它们的角色是扩展webpack引擎重要的第一步
compiler对象代表了完整的webpack环境配置,这个对象在启动webpack时被一次性实例化,可以简单理解为webpack实例,并配置好所有可操作的设置,包括options,loader和plugin。当在webpack环境中启用一个插件时,插件将受到compiler对象的引用,可以使用它来访问webpack的主环境
compilation对象代表一次资源版本构建,当运行webpack开发环境中间件时,每当检测一个文件变化,就会创建一个新的compilation,从而生成一组新的编译资源,一个compilation对象表现了当前的模块资源、编译生成资源、变化的文件、以及被跟踪依赖大的状态信息。compilation对象也提供了很多关键时机的回调,以供插件做自定义处理时选择使用,通过compilation也能读取到compiler对象
compiler和compilation区别在于:compiler代表了整个webpack从启动到关闭的生命周期,而compilation只是代表了一次新的编译
基本插件架构
插件是由具有apply方法的prototype对象所实例化出来的,这个apply方法在安装插件时,会被webpack compiler调用一次,apply方法可以接受一个webpack compiler对象的引用,从而可以在回调函数中访问到compiler对象。
1 | class HelloWorldPlugin { |
安装插件:
1 | // webpack.config.js |