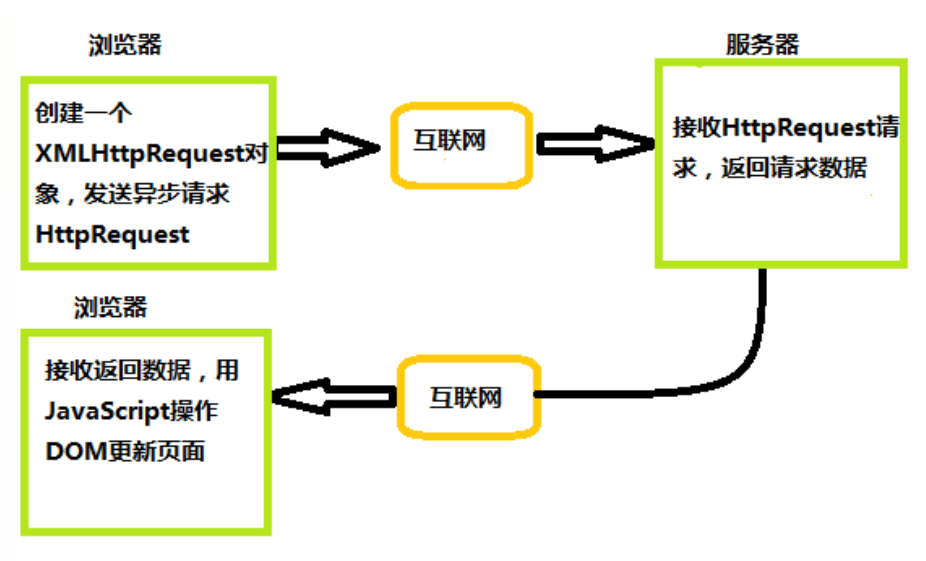
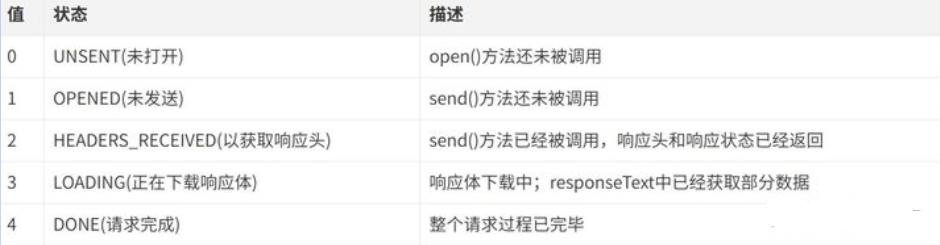
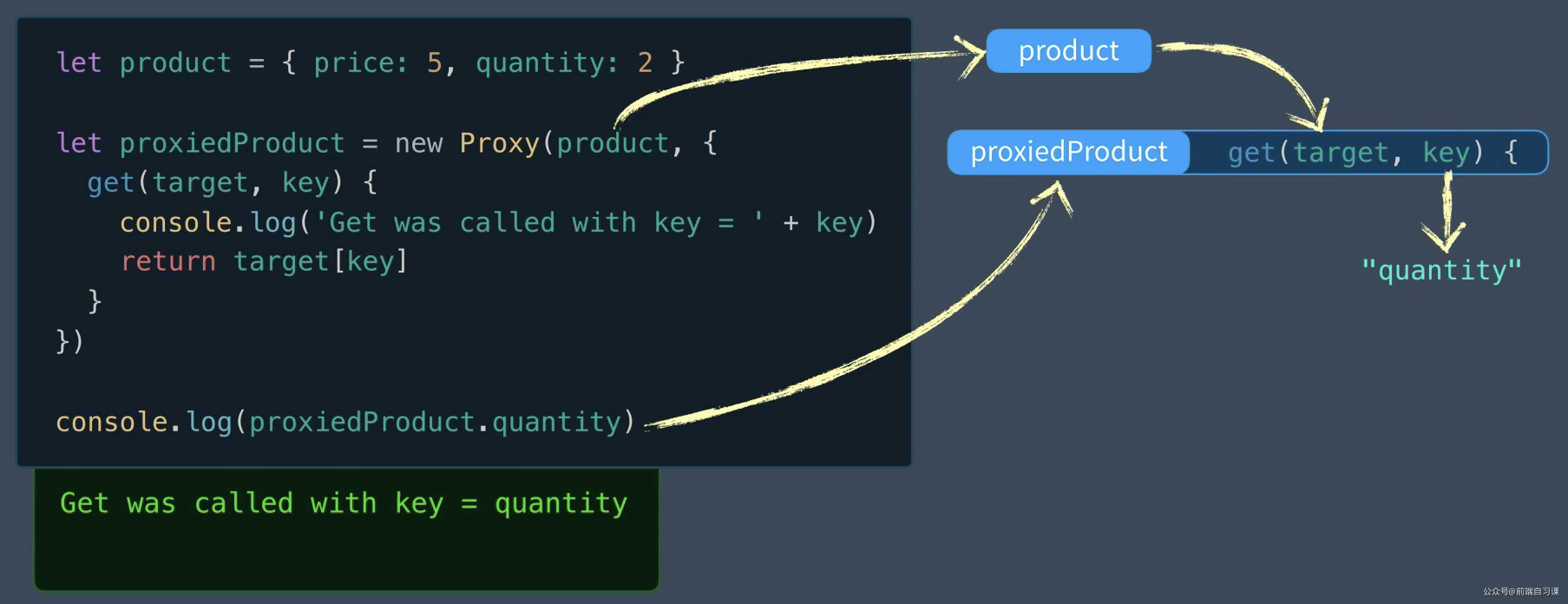
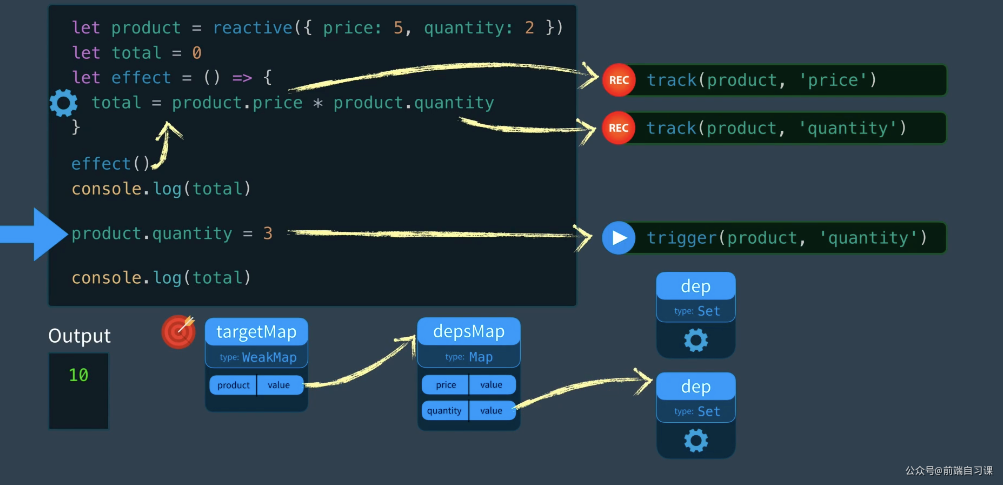
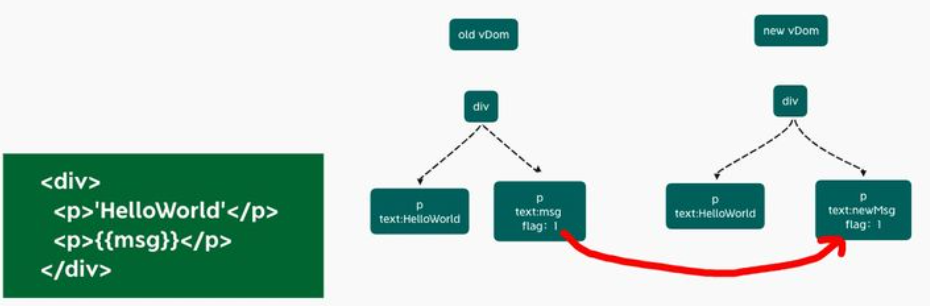
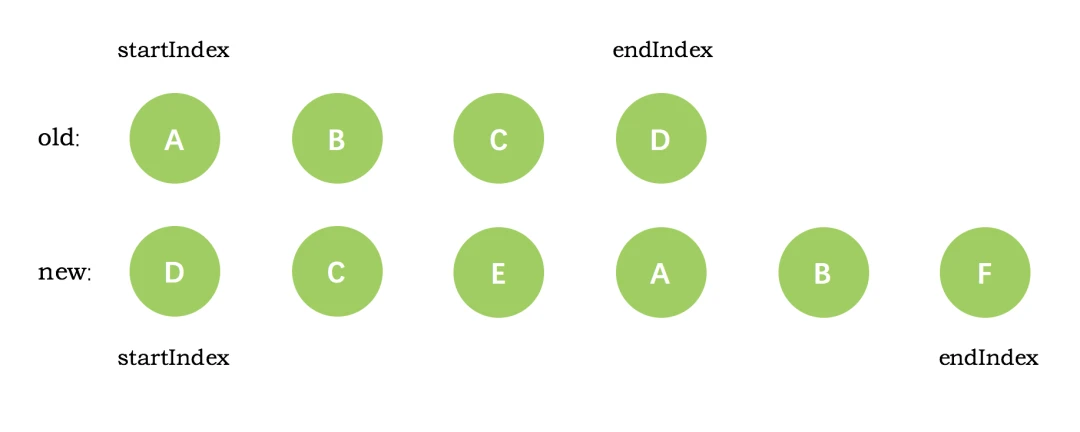
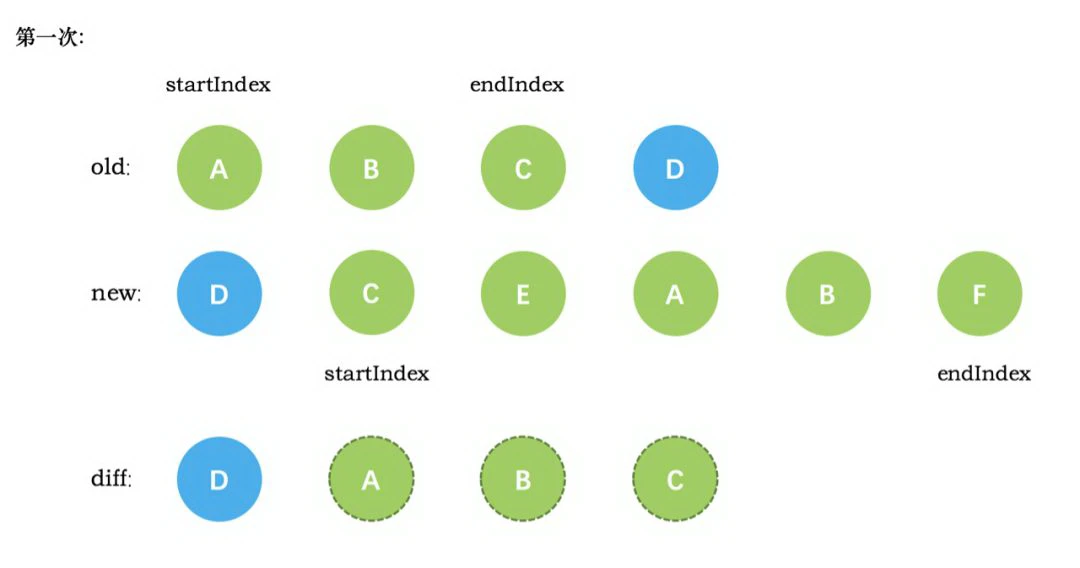
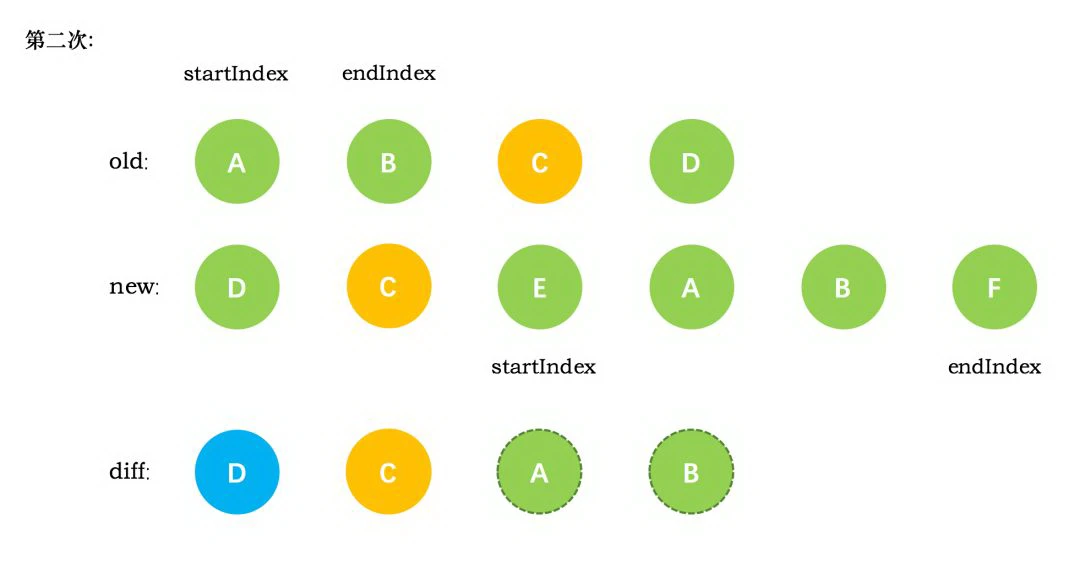
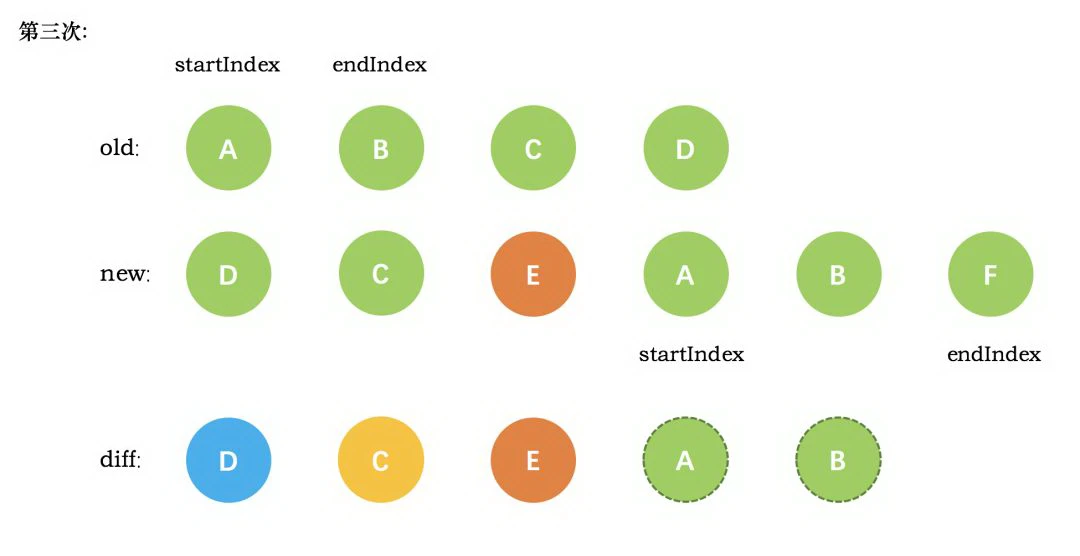
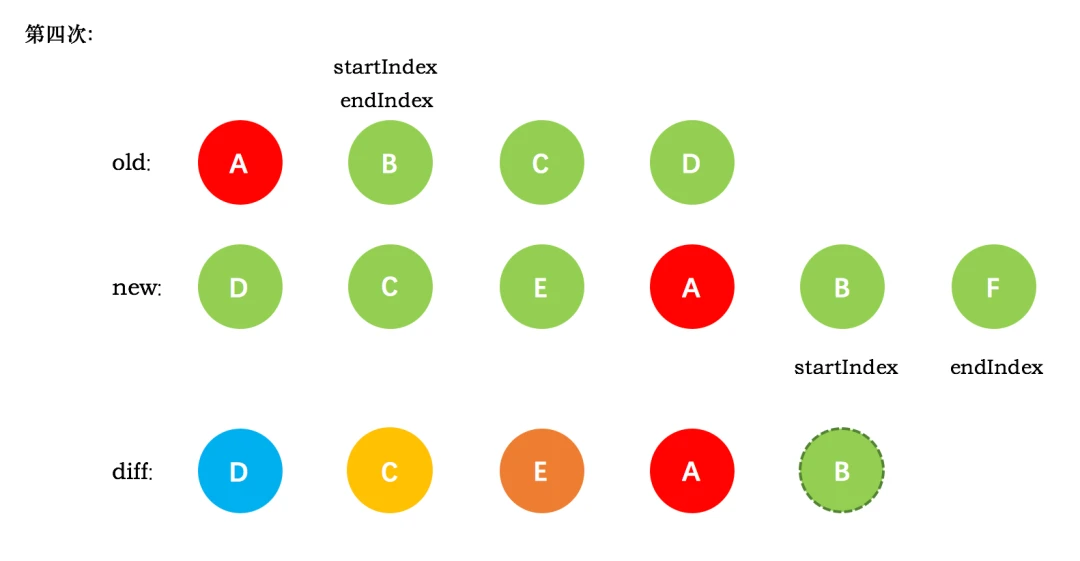
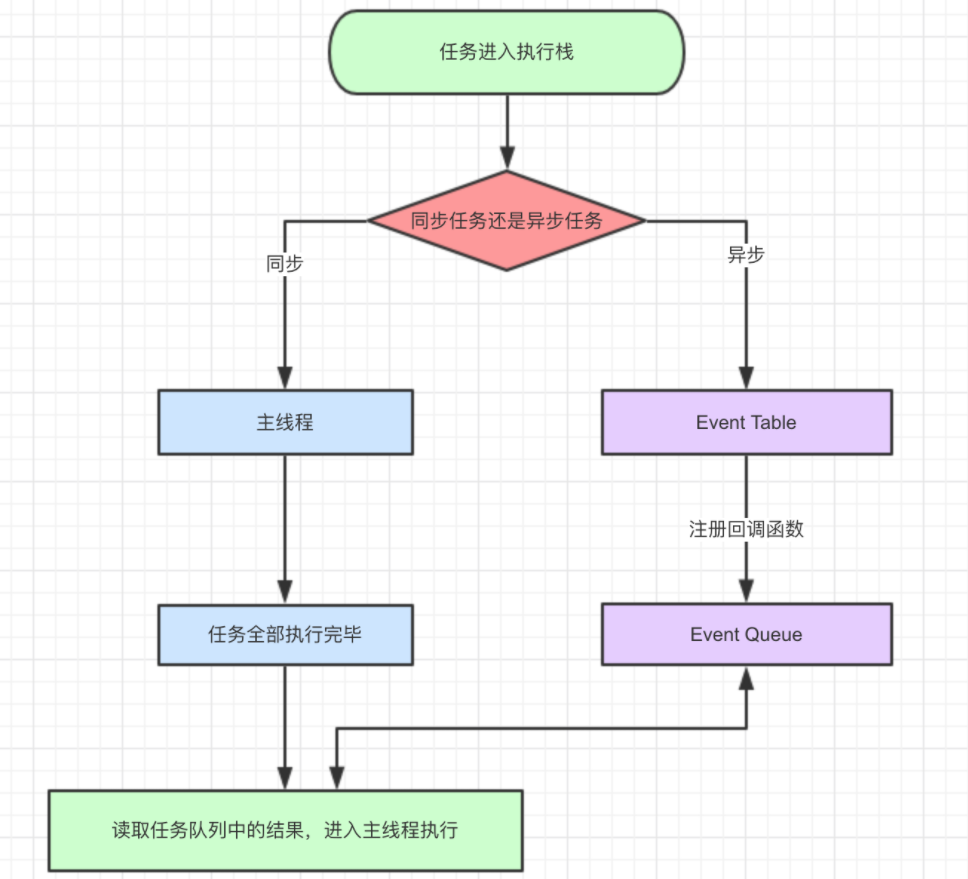
一、 Chrome架构:仅仅打开了一个页面,为什么有4个进程?
线程 VS 进程
多线程可以并行处理任务,但是线程是不能单独存在的,它是由进程来启动和管理的。 那什么又是进程呢?一个进程就是一个程序的运行实例。详细解释就是,启动一个程序的时候,操作系统会为该程序创建一块内存,用来存放代码、运行中的数据和一个执行任务的主线程,我们把这样的一个运行环境叫进程。
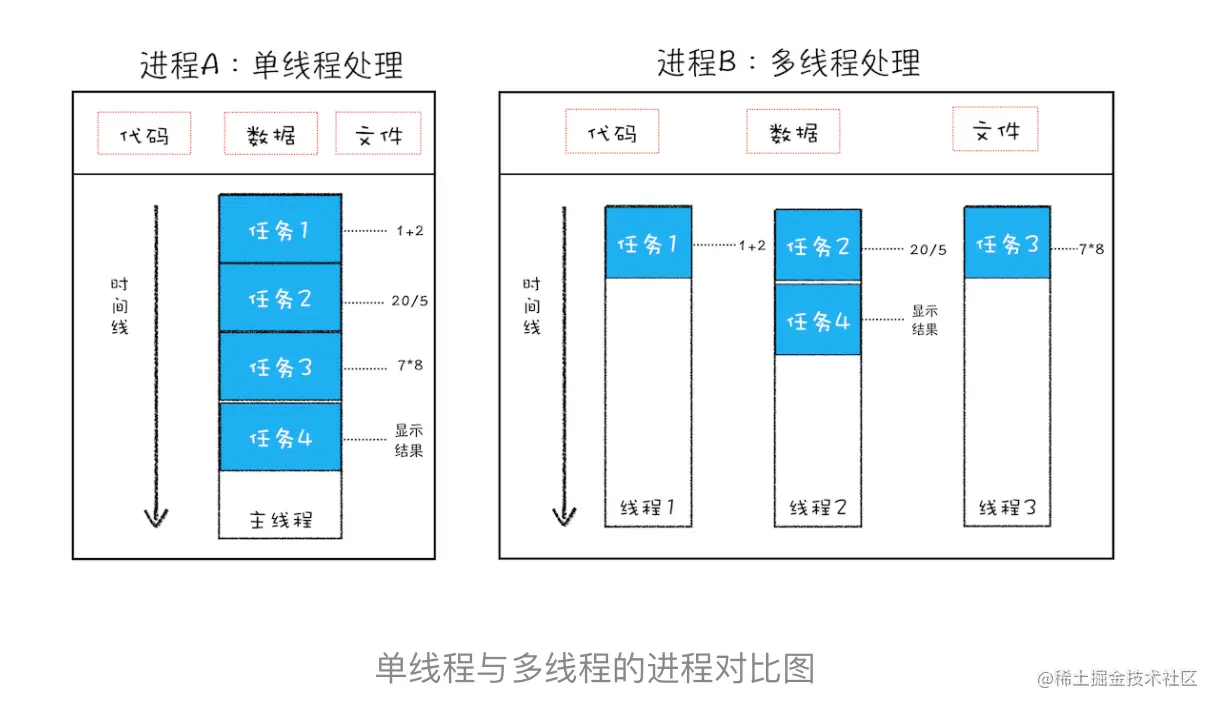 从图中看出,线程是依附于进程的,而进程中使用多线程并行能提高运算效率
从图中看出,线程是依附于进程的,而进程中使用多线程并行能提高运算效率
总结:
- 进程中的任一线程执行出错,都会导致整个进程的崩溃
- 线程之间共享进程中的数据。
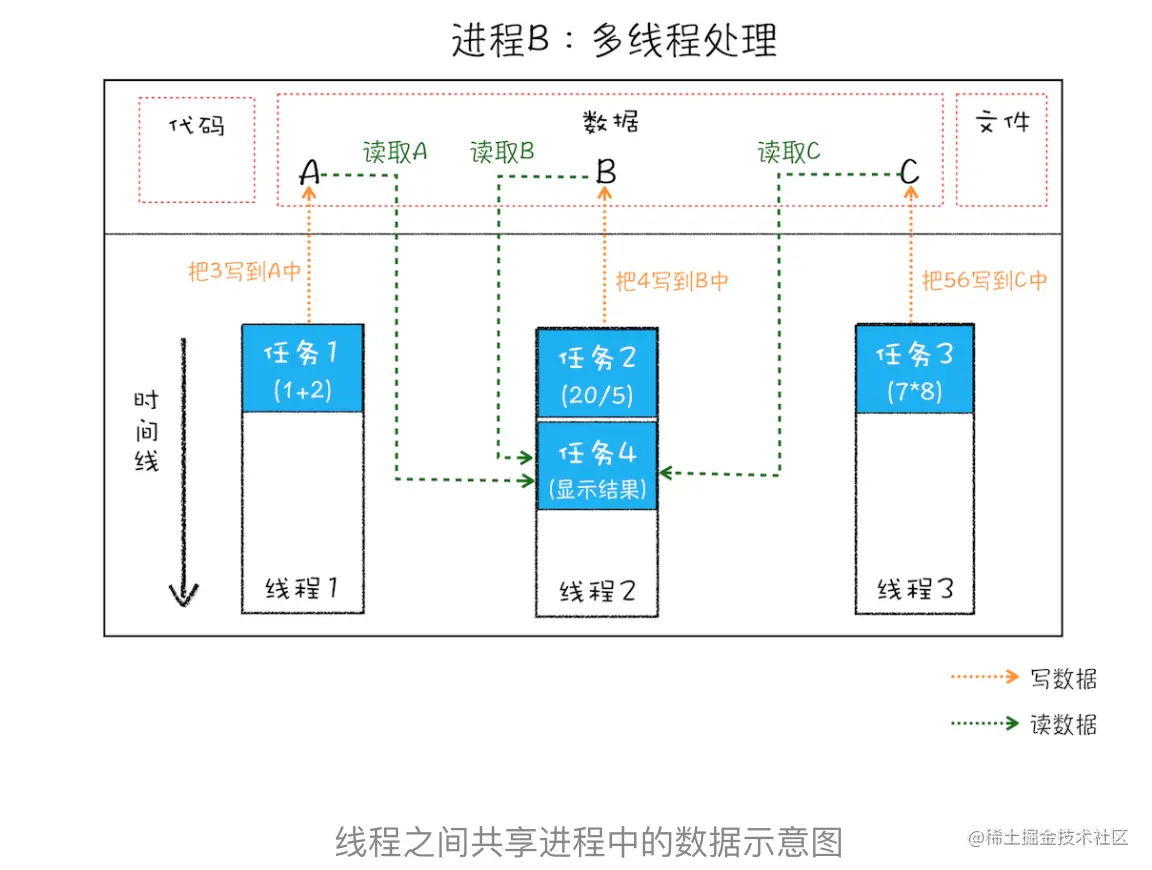 3. 当一个进程关闭之后,操作系统会回收进程所占用的内存
3. 当一个进程关闭之后,操作系统会回收进程所占用的内存
\4. 进程之间的内容相互隔离
目前浏览器的多进程架构
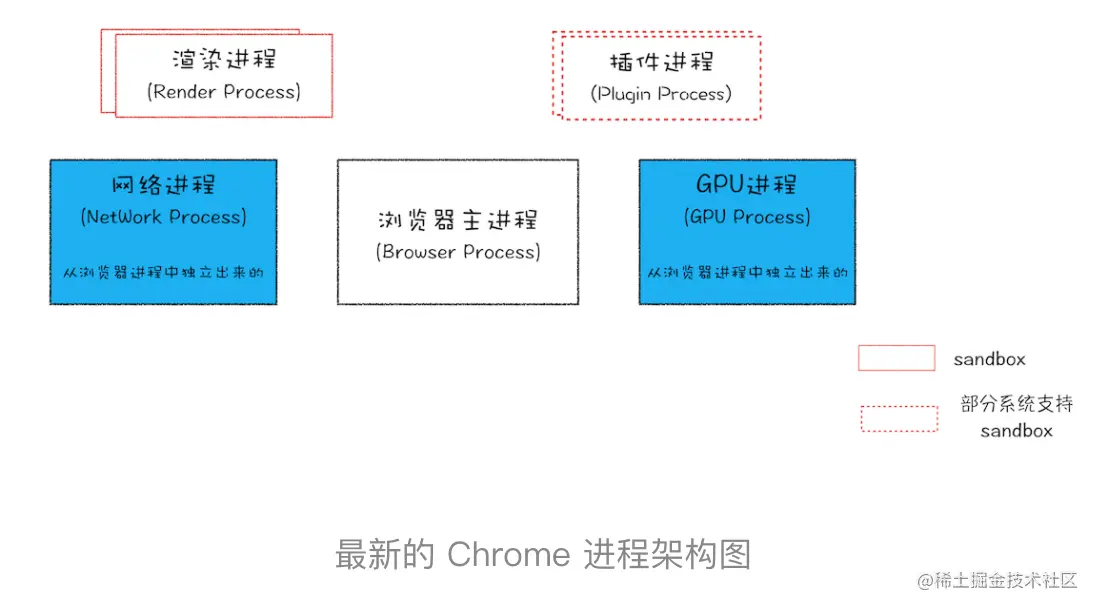
最新的chrome浏览器包括: 1个浏览器主进程,1个GPU进程,1个网络进程,多个渲染进程和多个插件进程。
分析这几个进程的功能:
- 浏览器进程:
主要负责界面展示,用户交互,子进程管理,同时提供存储等功能。
- 渲染进程:
核心任务是将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页,排版引擎 Blink 和 JavaScript 引擎 V8 都是运行在该进程中,默认情况下,Chrome 会为每个 Tab 标签创建一个渲染进程。出于安全考虑,渲染进程都是运行在沙箱模式下。
- GPU进程
主要是用来实现 3D,CSS等效果
- 网络进程
主要负责页面的网络资源加载
- 插件进程
主要是负责插件的进程,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响
多进程架构带来优缺点:
优点: 提高了稳定性、流畅性和安全性
缺点:更高的资源占用,更复杂的体系架构
二、 TCP协议:如何保证页面文件能被完整送达浏览器?
在衡量 Web 页面性能的时候有一个重要的指标叫 “FP(First Paint)” ,是指 从页面加载到首次开始绘制的时长 。这个指标直接影响了用户的跳出率,更快的页面响应意味着更多的 PV、更高的参与度,以及更高的转化率。那什么影响 FP 指标呢?其中一个重要的因素是网络加载速度。
一个数据包的“旅程”
- IP: 把数据包送达目的主机
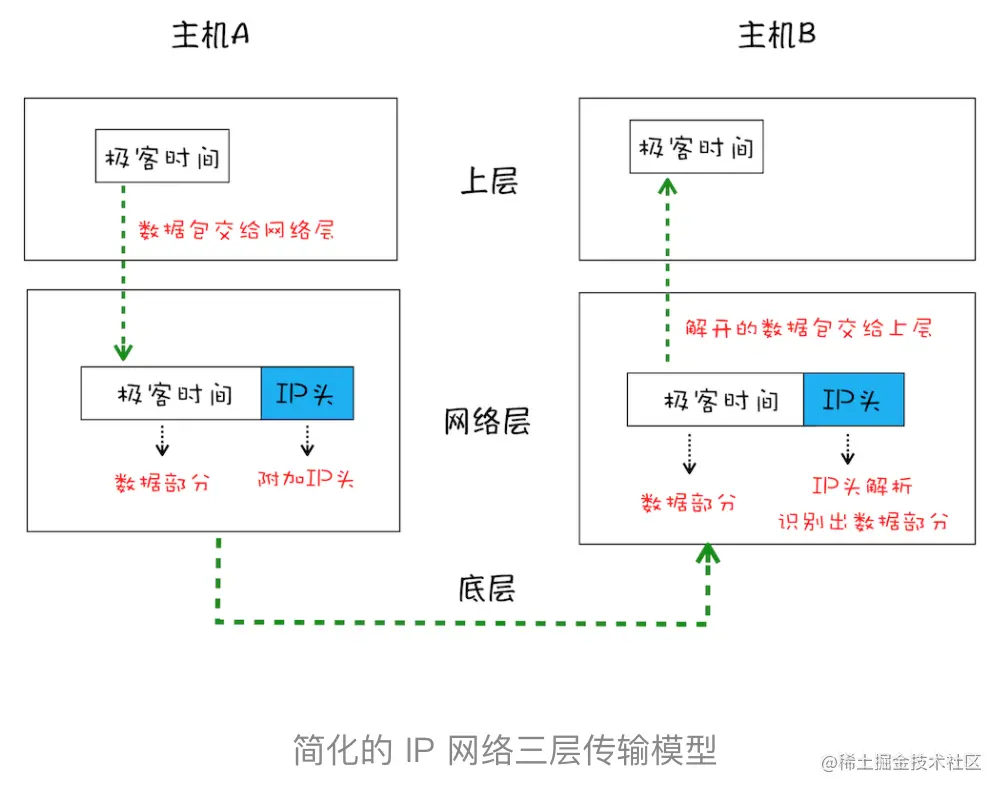 2. UDP:把数据包送达应用程序
2. UDP:把数据包送达应用程序  增加了UDP传输层
增加了UDP传输层
\3. TCP:把数据完整地送达应用程序
UDP的问题:
- 数据包在传输过程中容易丢失;
- 大文件会被拆成很多小的数据包来传输,这些小的数据包会经过不同的路由,并在不同的时间到达接收端,而UDP协议并不知道如何组装这些数据包,从而把这些数据包还原成完整的文件。
TCP的特点:
- 对于数据包丢失的情况,TCP提供重传机制;
- TCP引入了数据包排序机制,用来保证把乱序的数据包组合成一个完整的文件。
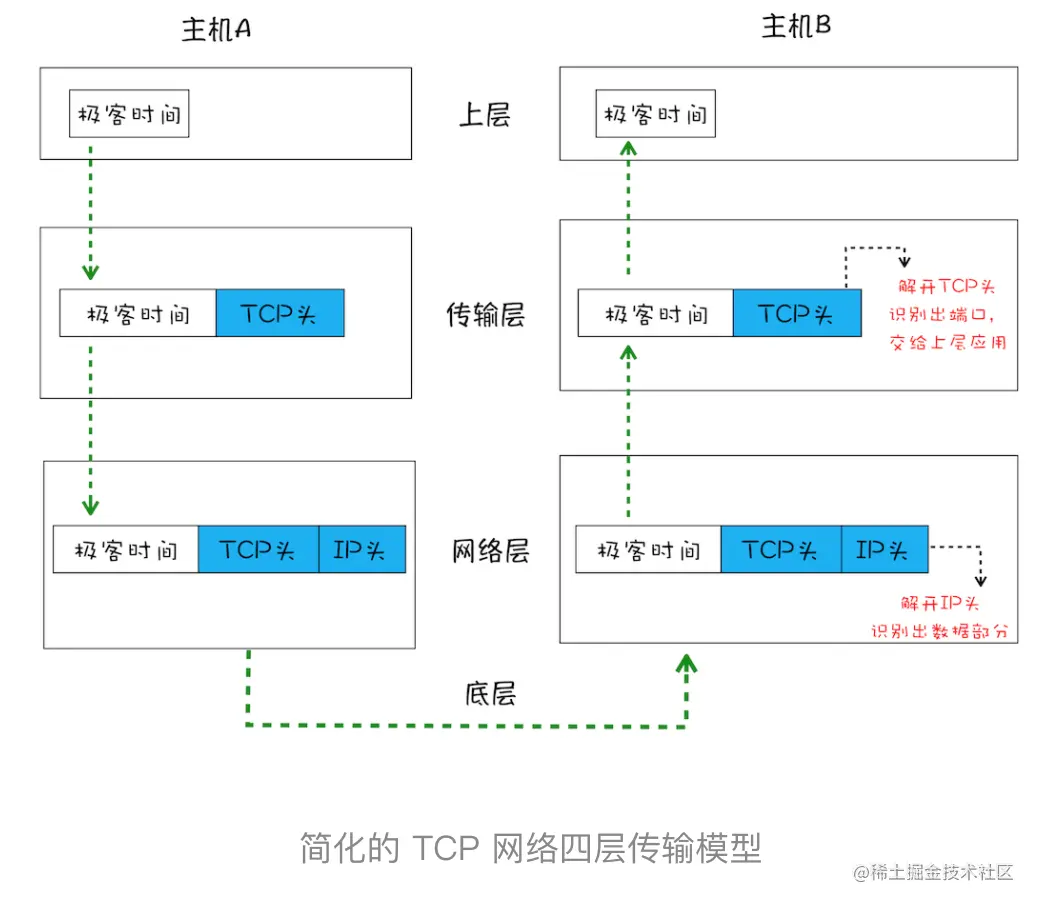
一个完整的TCP连接的生命周期:
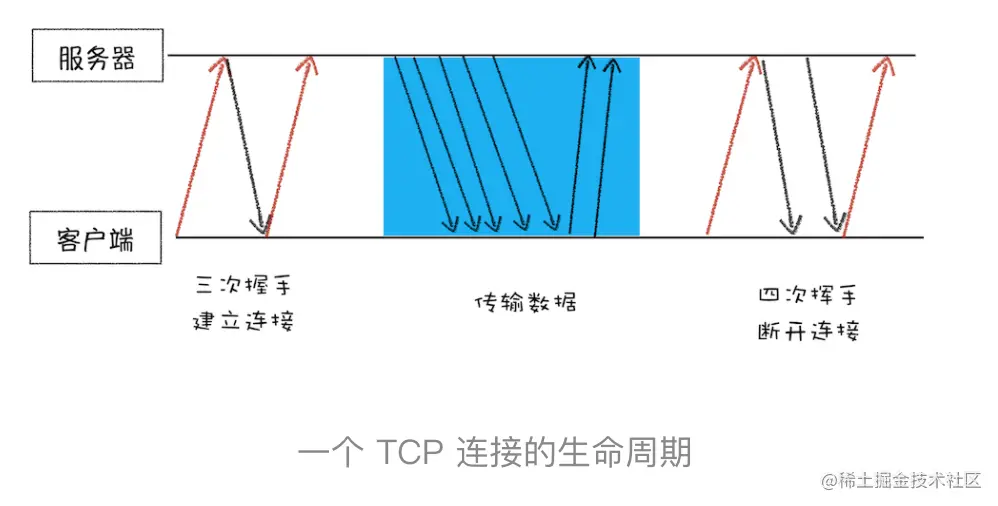
总结:
- 互联网中的数据是通过数据包来传输的,数据包在传输过程中容易丢失或出错。
- IP 负责把数据包送达目的主机。
- UDP 负责把数据包送达具体应用。
- 而 TCP 保证了数据完整地传输,它的连接可分为三个阶段:建立连接、传输数据和断开连接。
三、HTTP请求流程: 为什么很多站点第二次打开速度会很快?
HTTP 是一种允许浏览器向服务器获取资源的协议,是 Web 的基础
浏览器发起 HTTP 请求的流程
- 构建请求
1 | GET /index.html HTTP1.1 |
- 查找缓存
浏览器缓存是一种在本地保存资源副本,以供下次请求时直接使用的技术。
- 准备IP地址和端口
第一步浏览器会请求 DNS 返回域名对应的 IP。当然浏览器还提供了 DNS 数据缓存服务,如果某个域名已经解析过了,那么浏览器会缓存解析的结果,以供下次查询时直接使用,这样也会减少一次网络请求。
- 等待 TCP 队列
Chrome 有个机制,同一个域名同时最多只能建立 6 个 TCP 连接,如果在同一个域名下同时有 10 个请求发生,那么其中 4 个请求会进入排队等待状态,直至进行中的请求完成。
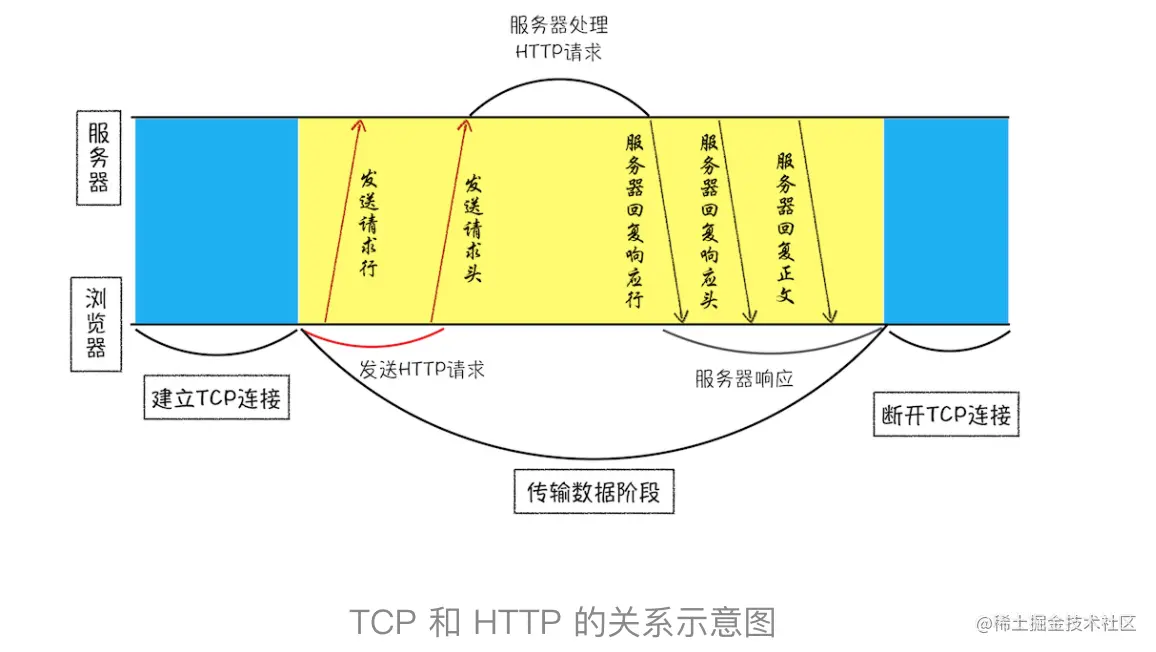
- 建立 TCP 连接
- 发送 HTTP 请求
浏览器是如何发送请求信息给服务器的?
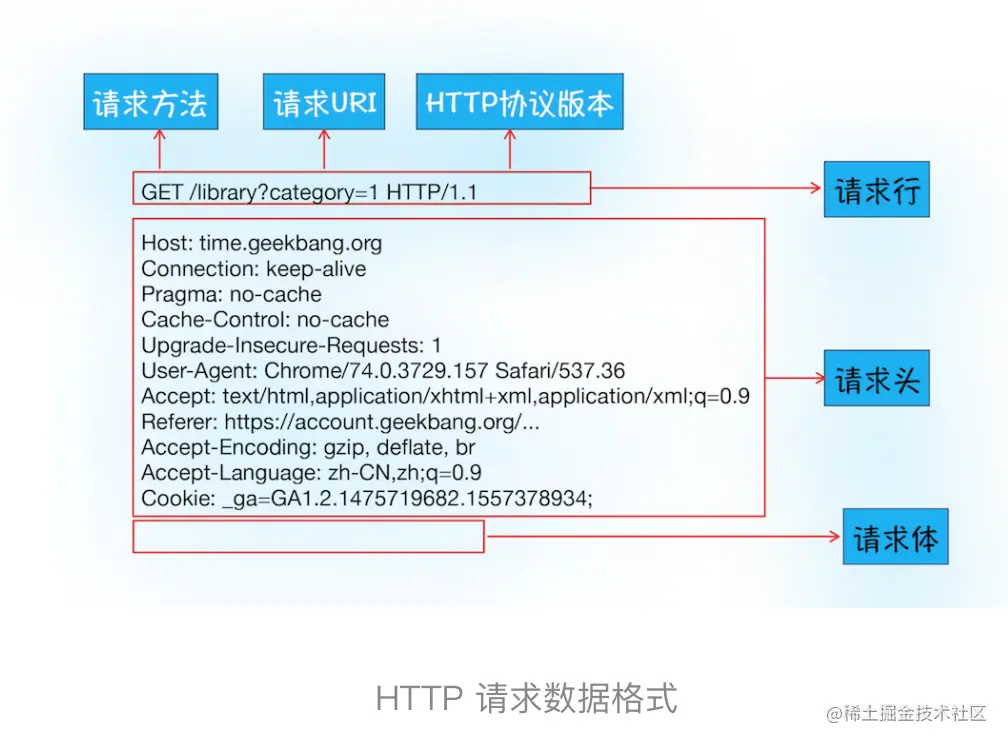 首先浏览器会向服务器发送请求行,它包括了请求方法、请求 URI(Uniform Resource Identifier)和 HTTP 版本协议。
首先浏览器会向服务器发送请求行,它包括了请求方法、请求 URI(Uniform Resource Identifier)和 HTTP 版本协议。
服务端处理 HTTP 请求流程
- 返回请求
1 | curl -i https://time.geekbang.org/ |
注意这里加上了-i是为了返回响应行、响应头和响应体的数据
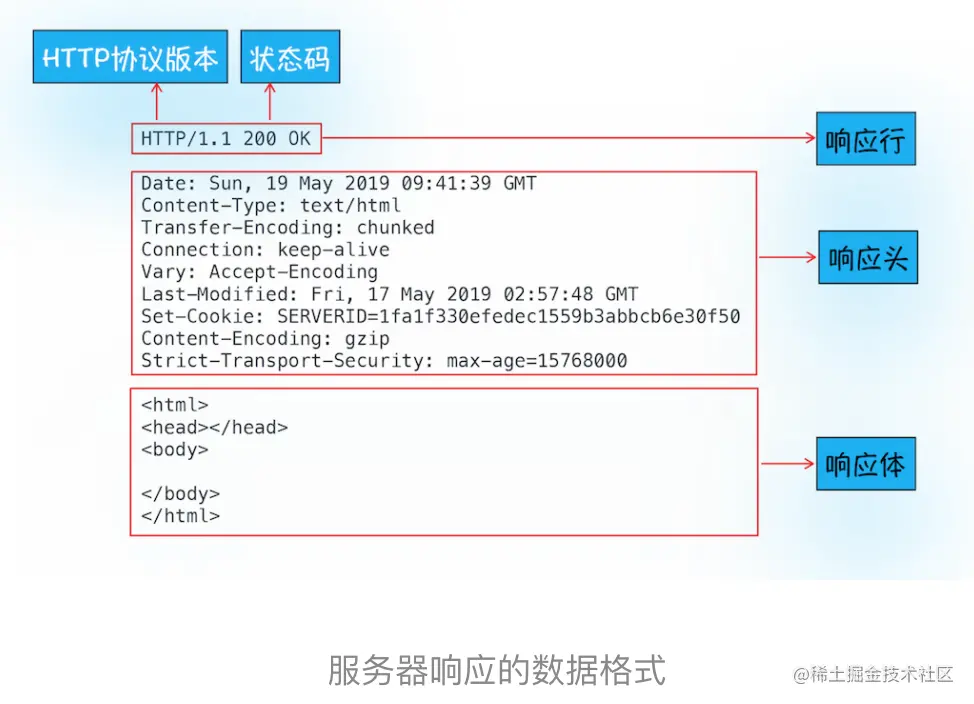
i. 首先服务器会返回 响应行,包括协议和状态码。
ii. 然后发送响应头,包括
- 服务器生成返回数据的时间
- 返回的数据类型(JSON、HTML、流媒体等类型,),以及服务端要在客户端保存的cookie等信息
iii. 发送响应体,包含了HTML的实际内容
- 断开连接
通常情况下,一旦服务器向客户端返回了请求数据,它就要关闭 TCP 连接。不过如果浏览器或者服务器在其头信息中加入了: Connection:Keep-Alive 那么 TCP 连接在发送后将仍然保持打开状态,这样浏览器就可以继续通过同一个 TCP 连接发送请求。保持 TCP 连接可以省去下次请求时需要建立连接的时间,提升资源加载速度。
- 重定向
curl -I geekbang.org 注意这里输入的参数是-I,和-i不一样,-I表示只需要获取响应头和响应行数据,而不需要获取响应体的数据,最终返回的数据如下图所示:  从图中知道,301告诉浏览器重定向,网址是 Location 字段的内容
从图中知道,301告诉浏览器重定向,网址是 Location 字段的内容
问题解答:
- 为什么很多站点第二次打开速度会很快?
如果第二次页面打开很快,主要是第一次加载页面过程中,缓存了一些耗时的数据。(DNS 缓存和页面资源缓存) 缓存处理的过程:
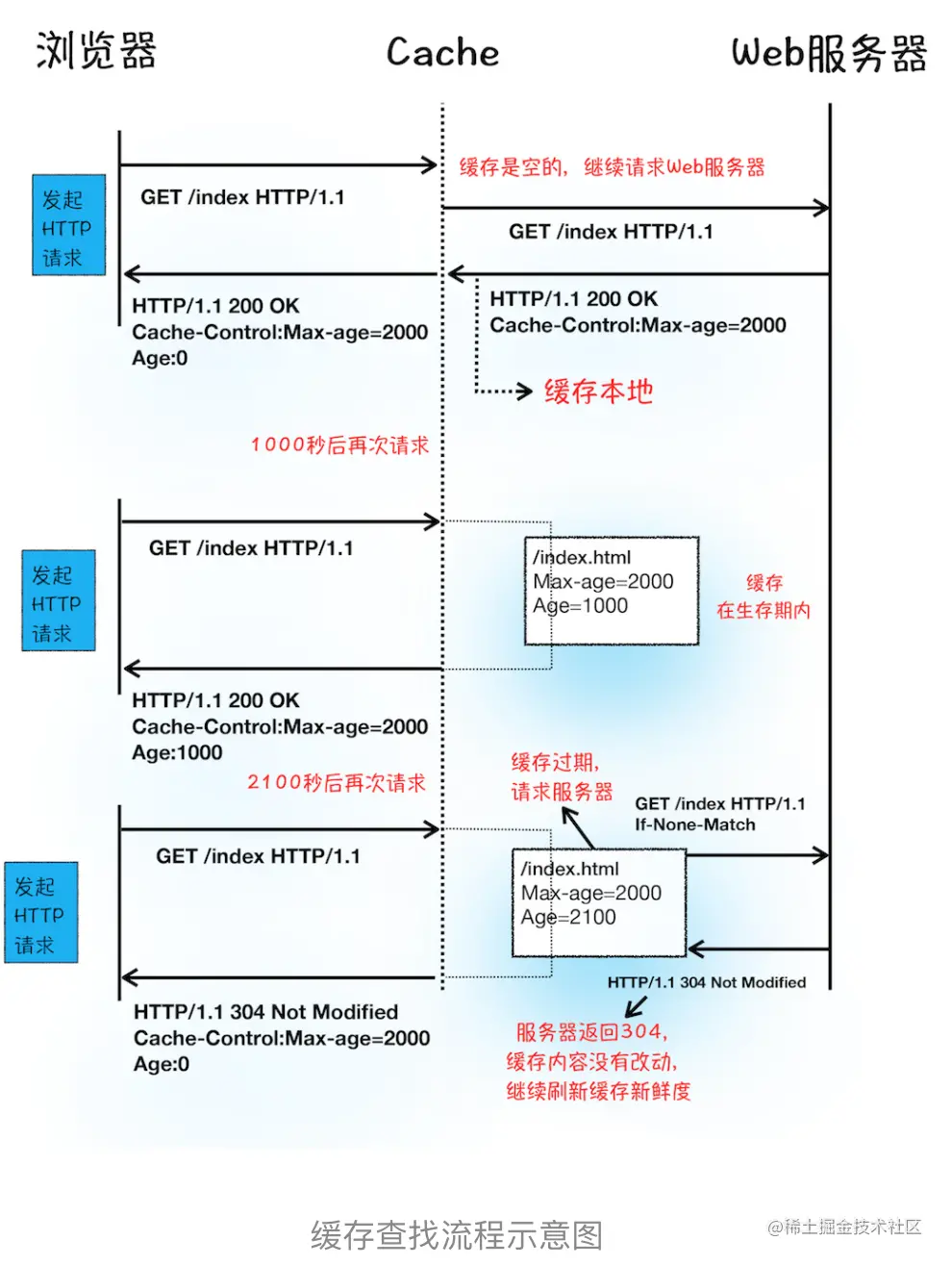
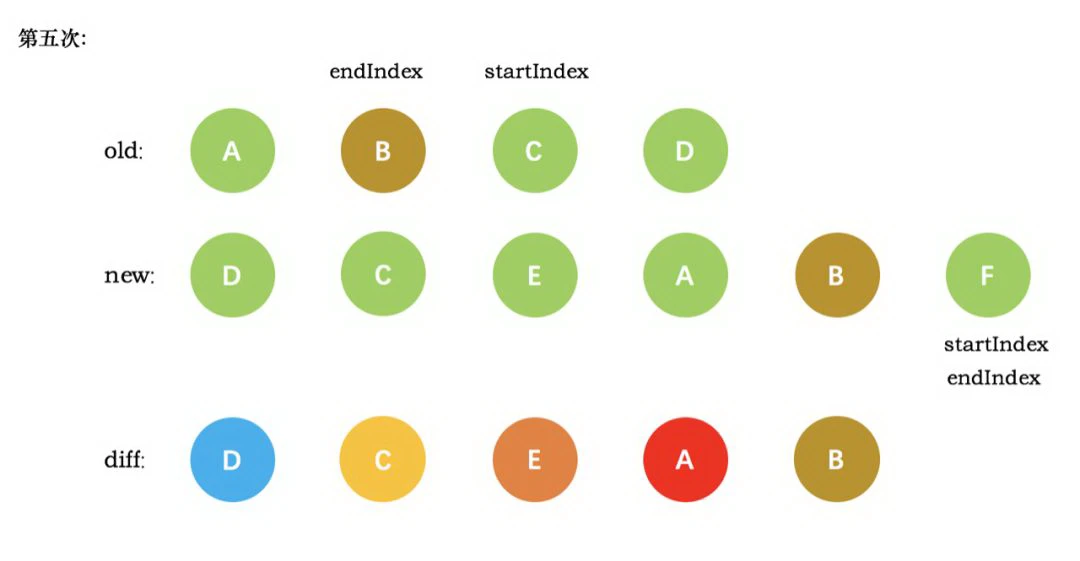
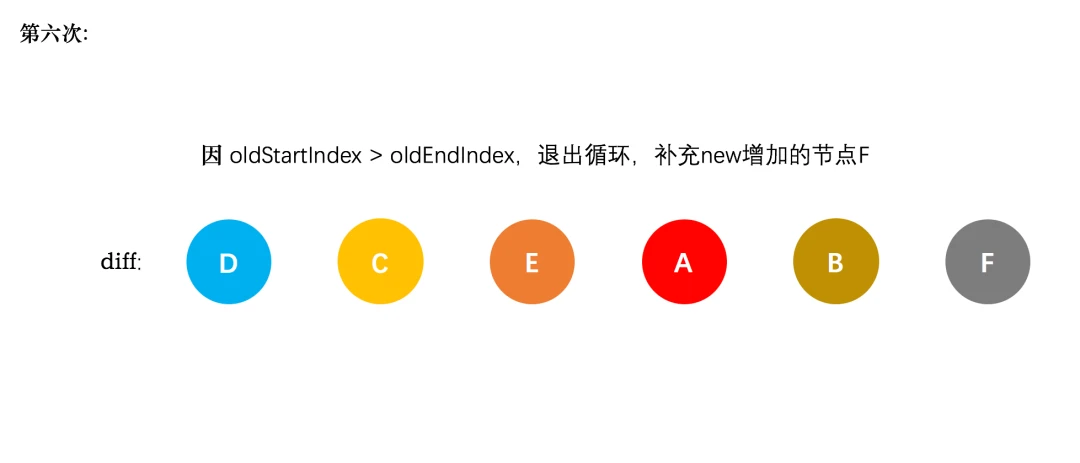
图中知:
- 第一次请求时,http response header,浏览器是通过响应头中的Cache-Control字段来设置是否缓存该资源。
- 如果缓存过期了,浏览器则会继续发起网络请求,并且在 HTTP 请求头中带上:
1 | If-None-Match:"4f80f-13c-3a1xb12a" |
- 没更新 => 304
- 更新了 => 最新的资源文件
简单说,DNS被缓存,节省查询解析时间 静态资源缓存在了本地,使用了本地副本,节省了时间
- 登录状态是如何保持的?
- 用户打开登录页面,在登录框里填入用户名和密码,点击确定按钮。点击按钮会触发页面脚本生成用户登录信息,然后调用 POST 方法提交用户登录信息给服务器。
- 服务器接收到浏览器提交的信息之后,查询后台,验证用户登录信息是否正确,如果正确的话,会生成一段表示用户身份的字符串,并把该字符串写到响应头的
Set-Cookie字段里,如下所示,然后把响应头发送给浏览器。
1 | Set-Cookie: UID=3431uad; |
- 浏览器在接收到服务器的响应头后,开始解析响应头,如果遇到响应头里含有 Set-Cookie 字段的情况,浏览器就会把这个字段信息保存到本地。比如把UID=3431uad保持到本地。
- 当用户再次访问时,浏览器会发起 HTTP 请求,但在发起请求之前,浏览器会读取之前保存的 Cookie 数据,并把数据写进请求头里的 Cookie 字段里(如下所示),然后浏览器再将请求头发送给服务器。
- 服务器在收到 HTTP 请求头数据之后,就会查找请求头里面的“Cookie”字段信息,当查找到包含UID=3431uad的信息时,服务器查询后台,并判断该用户是已登录状态,然后生成含有该用户信息的页面数据,并把生成的数据发送给浏览器。
- 浏览器在接收到该含有当前用户的页面数据后,就可以正确展示用户登录的状态信息了。
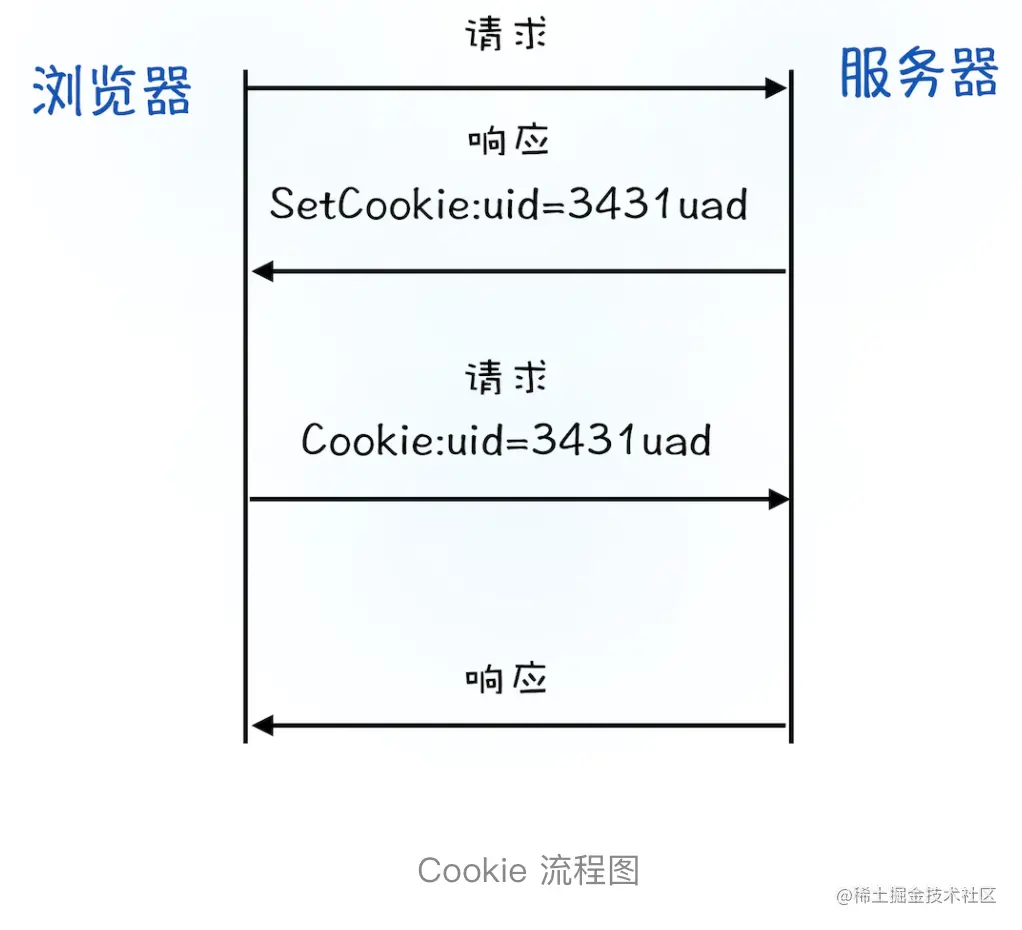
简单地说,如果服务器端发送的响应头内有 Set-Cookie 的字段,那么浏览器就会将该字段的内容保存到本地。当下次客户端再往该服务器发送请求时,客户端会自动在请求头中加入 Cookie 值后再发送出去。服务器端发现客户端发送过来的 Cookie 后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到该用户的状态信息。
附图:
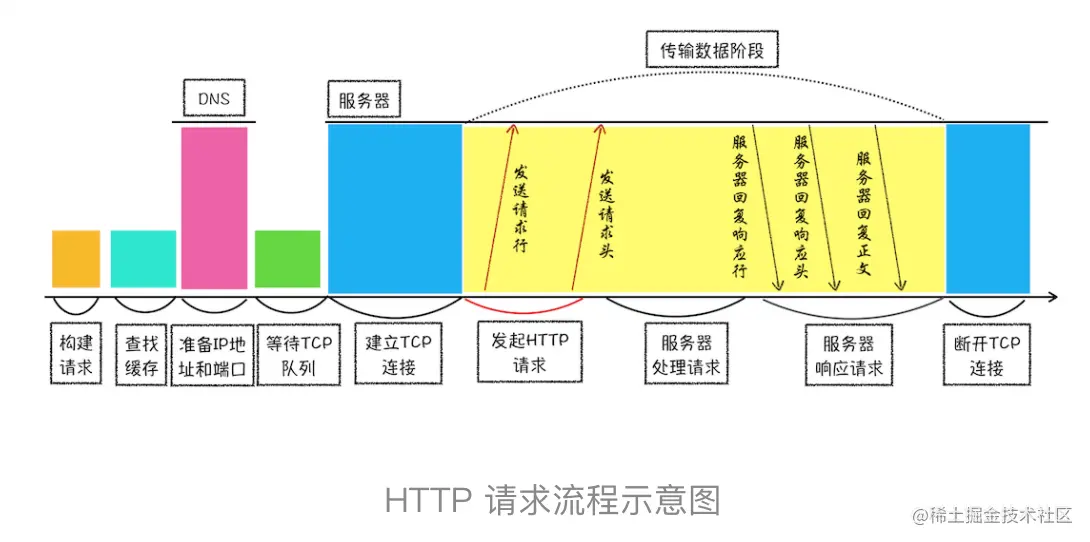
从图中可以看到,浏览器中的 HTTP 请求从发起到结束一共经历了如下八个阶段:构建请求、查找缓存、准备 IP 和端口、等待 TCP 队列、建立 TCP 连接、发起 HTTP 请求、服务器处理请求、服务器返回请求和断开连接。
四、 导航流程: 从输入URL到页面显示,这中间发生了什么?
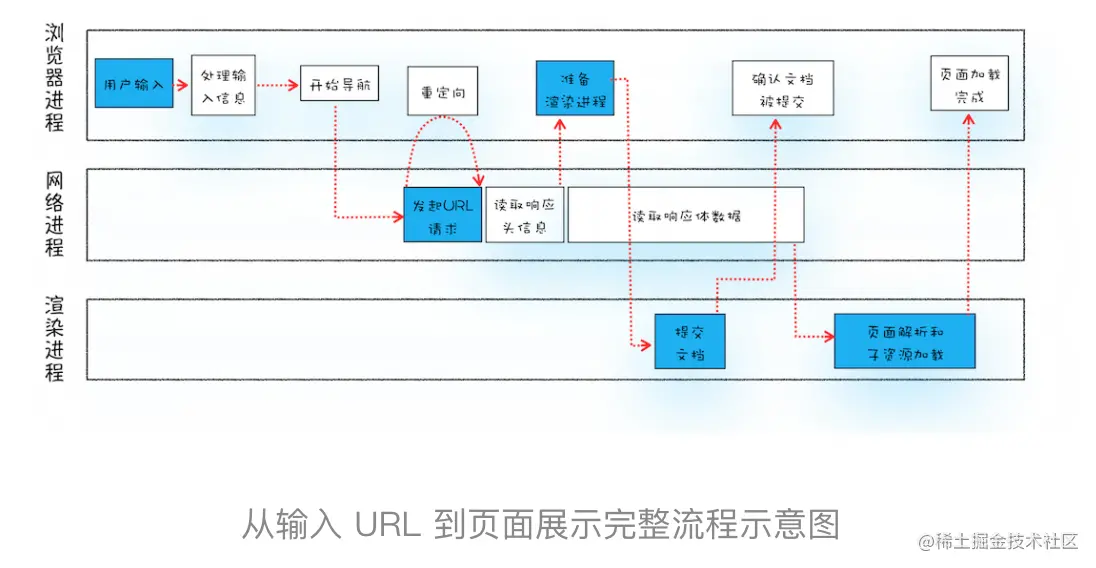
浏览器进程、渲染进程和网络进程的主要职责:
- 浏览器进程主要负责用户交互、子进程管理和文件存储等功能
- 网络进程是面向渲染进程和浏览器进程等提供网络下载功能。
- 渲染进程的主要职责是把从网络下载的HTML、Javascript、css、图片等资源解析为可以显示和交互的页面。
简单小结:
- 用户输入URL,浏览器会根据用户输入的信息判断是搜索还是网址,如果是搜索内容,就将搜索内容+默认搜索引擎合成新的URL;如果用户输入的内容符合URL规则,浏览器就会根据URL协议,在这段内容上加上协议合成合法的URL
- 用户输入完内容,按下回车键,浏览器导航栏显示loading状态,但是页面还是呈现前一个页面,这是因为新页面的响应数据还没有获得
- 浏览器进程浏览器构建请求行信息,会通过进程间通信(IPC)将URL请求发送给网络进程
GET /index.html HTTP1.1
- 网络进程获取到URL,先去本地缓存中查找是否有缓存文件,如果有,拦截请求,直接200返回;否则,进入网络请求过程
- 网络进程请求:第一步进行DNS解析,返回域名对应的IP和端口号,如果之前DNS数据缓存服务缓存过当前域名信息,就会直接返回缓存信息;否则,发起请求获取根据域名解析出来的IP和端口号,如果没有端口号,http默认80,https默认443。如果是https请求,还需要建立TLS连接。
- Chrome 有个机制,同一个域名同时最多只能建立 6 个TCP 连接,如果在同一个域名下同时有 10 个请求发生,那么其中 4 个请求会进入排队等待状态,直至进行中的请求完成。如果当前请求数量少于6个,会直接建立TCP连接。
- TCP三次握手建立连接,http请求加上TCP头部——包括源端口号、目的程序端口号和用于校验数据完整性的序号,向下传输
- 网络层在数据包上加上IP头部——包括源IP地址和目的IP地址,继续向下传输到底层
- 底层通过物理网络传输给目的服务器主机
- 目的服务器主机网络层接收到数据包,解析出IP头部,识别出数据部分,将解开的数据包向上传输到传输层
- 目的服务器主机传输层获取到数据包,解析出TCP头部,识别端口,将解开的数据包向上传输到应用层
- 应用层HTTP解析请求头和请求体,如果需要重定向,HTTP直接返回HTTP响应数据的状态code301或者302,同时在请求头的Location字段中附上重定向地址,浏览器会根据code和Location进行重定向操作;如果不是重定向,首先服务器会根据 请求头中的If-None-Match 的值来判断请求的资源是否被更新,如果没有更新,就返回304状态码,相当于告诉浏览器之前的缓存还可以使用,就不返回新数据了;否则,返回新数据,200的状态码,并且如果想要浏览器缓存数据的话,就在相应头中加入字段:
Cache-Control:Max-age=2000 响应数据又顺着应用层——传输层——网络层——底层——网络层——传输层——应用层的顺序返回到网络进程
- 数据传输完成,TCP四次挥手断开连接。如果,浏览器或者服务器在HTTP头部加上如下信息,TCP就一直保持连接。保持TCP连接可以省下下次需要建立连接的时间,提高资源加载速度
Connection:Keep-Alive
- 网络进程将获取到的数据包进行解析,根据响应头中的Content-type来判断响应数据的类型,如果是字节流类型,就将该请求交给下载管理器,该导航流程结束,不再进行;如果是text/html类型,就通知浏览器进程获取到文档准备渲染
- 浏览器进程获取到通知,根据当前页面B是否是从页面A打开的并且和页面A是否是同一个站点(根域名和协议一样就被认为是同一个站点),如果满足上述条件,就复用之前网页的进程,否则,新创建一个单独的渲染进程
- 浏览器进程会发出“提交文档”的消息给渲染进程,渲染进程收到消息后,会和网络进程建立传输数据的“管道”,文档数据传输完成后,渲染进程会返回“确认提交”的消息给浏览器进程
- 浏览器进程收到“确认提交”的消息后,会更新浏览器的页面状态,包括了安全状态、地址栏的 URL、前进后退的历史状态,并更新web页面,此时的web页面是空白页
- 渲染进程对文档进行页面解析和子资源加载,HTML 通过HTM 解析器转成DOM Tree(二叉树类似结构的东西),CSS按照CSS 规则和CSS解释器转成CSSOM TREE,两个tree结合,形成render tree(不包含HTML的具体元素和元素要画的具体位置),通过Layout可以计算出每个元素具体的宽高颜色位置,结合起来,开始绘制,最后显示在屏幕中新页面显示出来
笔记:
- curl -I + URL的命令是接收服务器返回的响应头的信息
1 | curl -I http://time.geekbang.org/ |
- 同一站点(same-site)
协议/根域名相同 例如:
1 | https://time.geekbang.org |
他们都属于是同一站点,因为它们的协议都是HTTPS,而且根域名也都是 geekbang.org
process-per-site-instance 策略:
如果从一个页面打开了另一个新页面,而新页面和当前页面属于同一站点的话,那么新页面会复用父页面的渲染进程
五、 渲染流程:HTML、CSS和 Javascript,是如何变成页面的?
按照渲染的时间顺序,流水线分为如下几个子阶段: 构建Dom树 => 样式计算 => 布局阶段 => 分层 => 绘制 => 分块 => 栅格化 => 合成
1. 构建DOM树
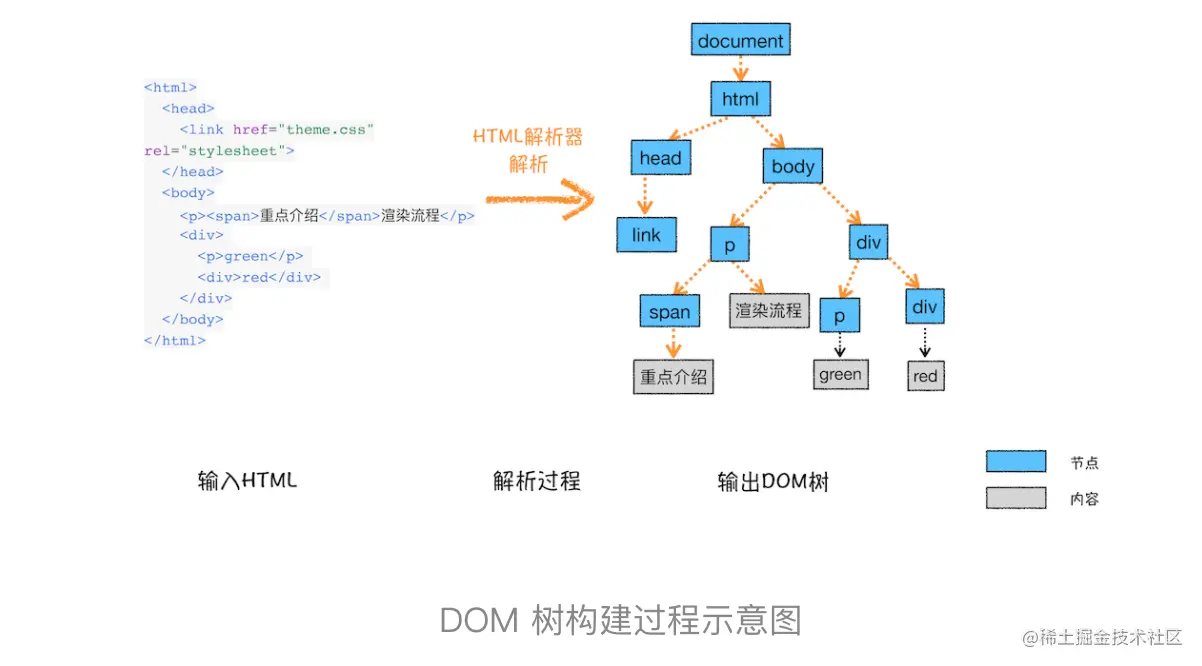
2. 样式计算
- 把CSS转换为浏览器能够理解的结构
- 转换样式表中的属性值,使其标准化
- 计算出 DOM 树中每个节点的具体样式(css继承和层叠规则)
3.布局阶段
- 创建布局树
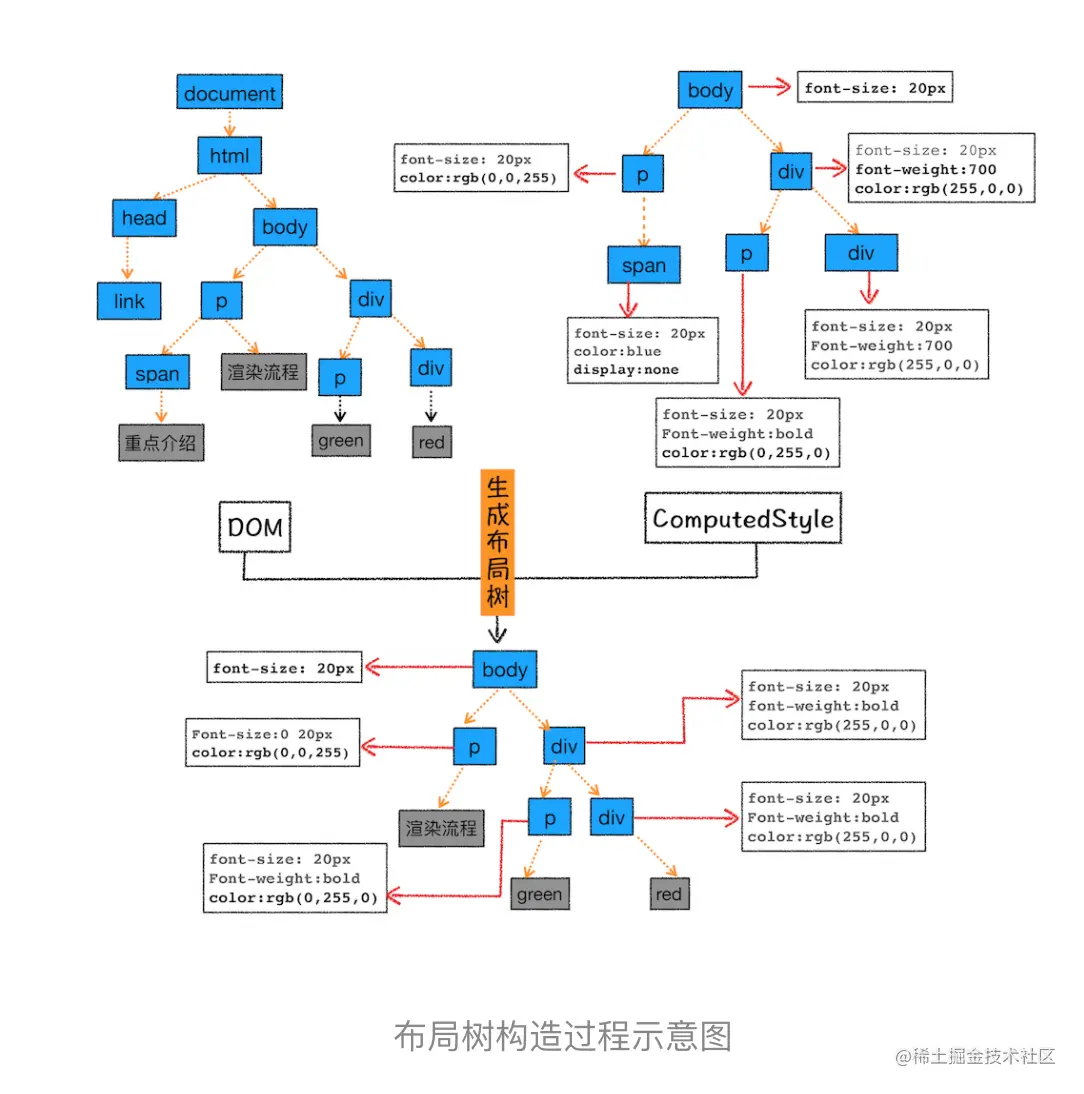 为了构建布局树,浏览器大体上完成了下面这些工作:
为了构建布局树,浏览器大体上完成了下面这些工作:
- 遍历DOM树中的所有的可见节点,并把这些节点添加到布局树中;
- 而不可见节点会被布局树忽略掉。
- 布局计算
4. 分层
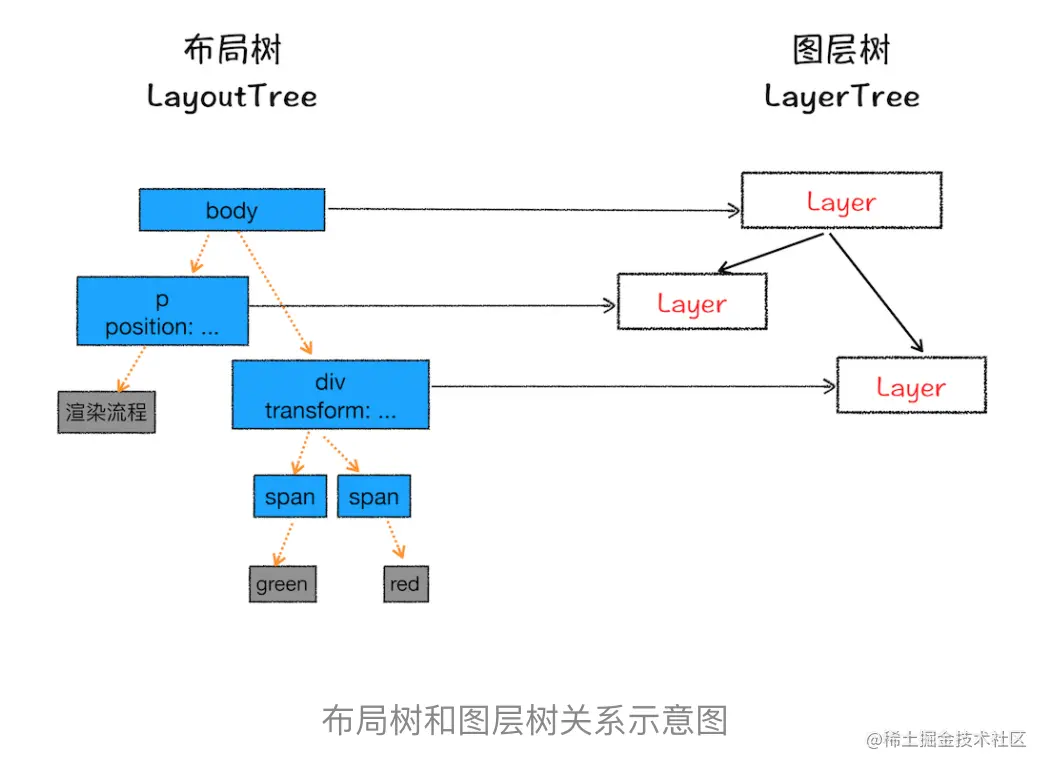 渲染引擎会为哪些特定的节点创建新的图层呢?
渲染引擎会为哪些特定的节点创建新的图层呢?
- 拥有层叠上下文属性的元素会被提升为单独的一层。
- 需要剪裁(clip)的地方也会被创建为图层
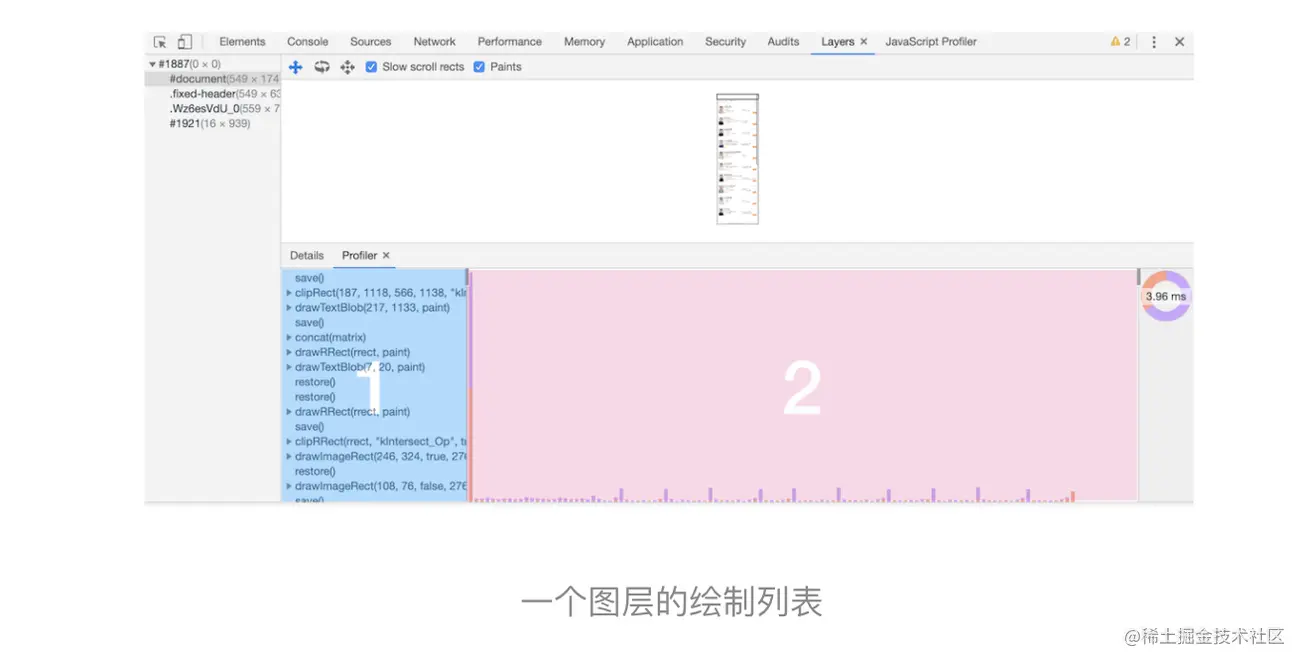
5. 图层绘制
6. 栅格化(raster)操作
是指将图块转换为位图 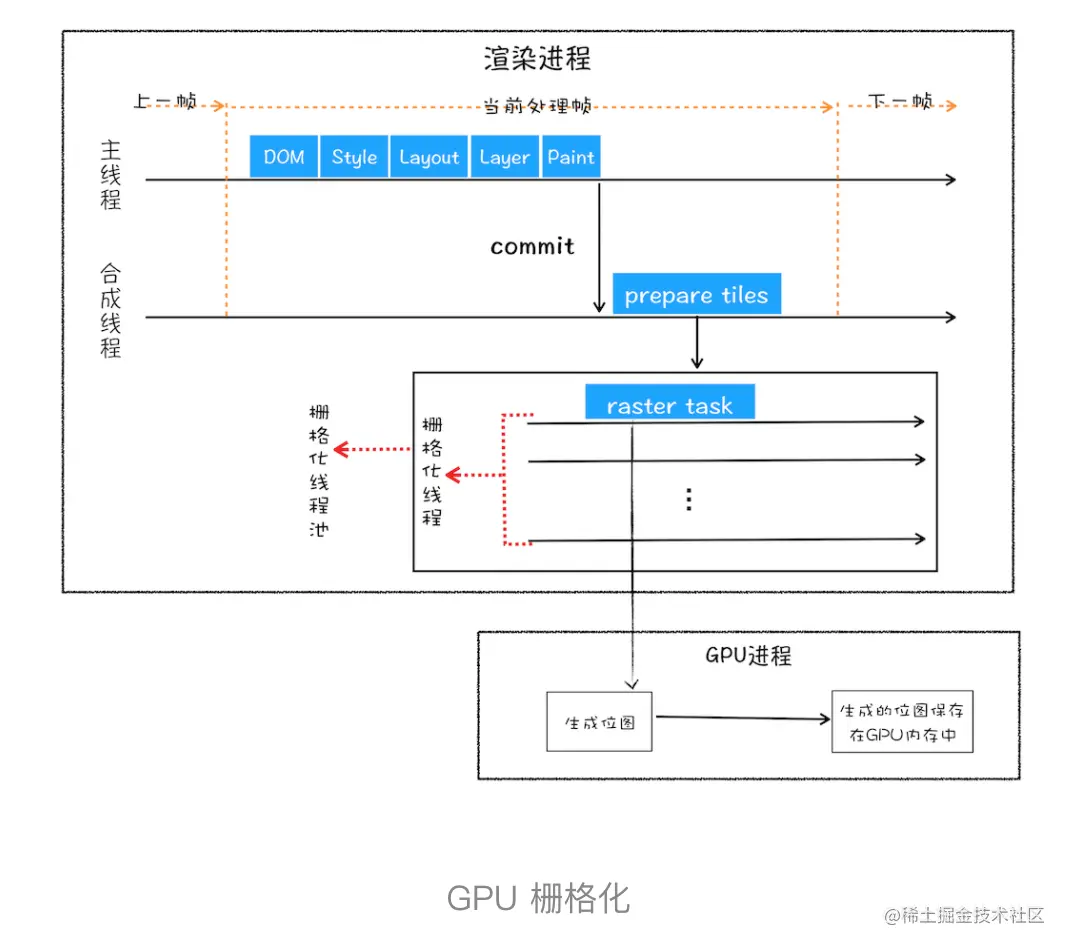 从图中可以看出,渲染进程把生成图块的指令发送给 GPU,然后在 GPU 中执行生成图块的位图,并保存在 GPU 的内存中。
从图中可以看出,渲染进程把生成图块的指令发送给 GPU,然后在 GPU 中执行生成图块的位图,并保存在 GPU 的内存中。
7. 合成和显示
图块都被光栅化后,合成线程生成一个绘制图块的命令“DrawQuad”,然后将命令提交给浏览器进程。 浏览器进程里的viz组件,用来接受合成线程发过来的DrawQuad命令,然后根据DrawQuad命令,将其页面内容绘制到内存中,最后在将内存显示在屏幕上
渲染流水线大总结
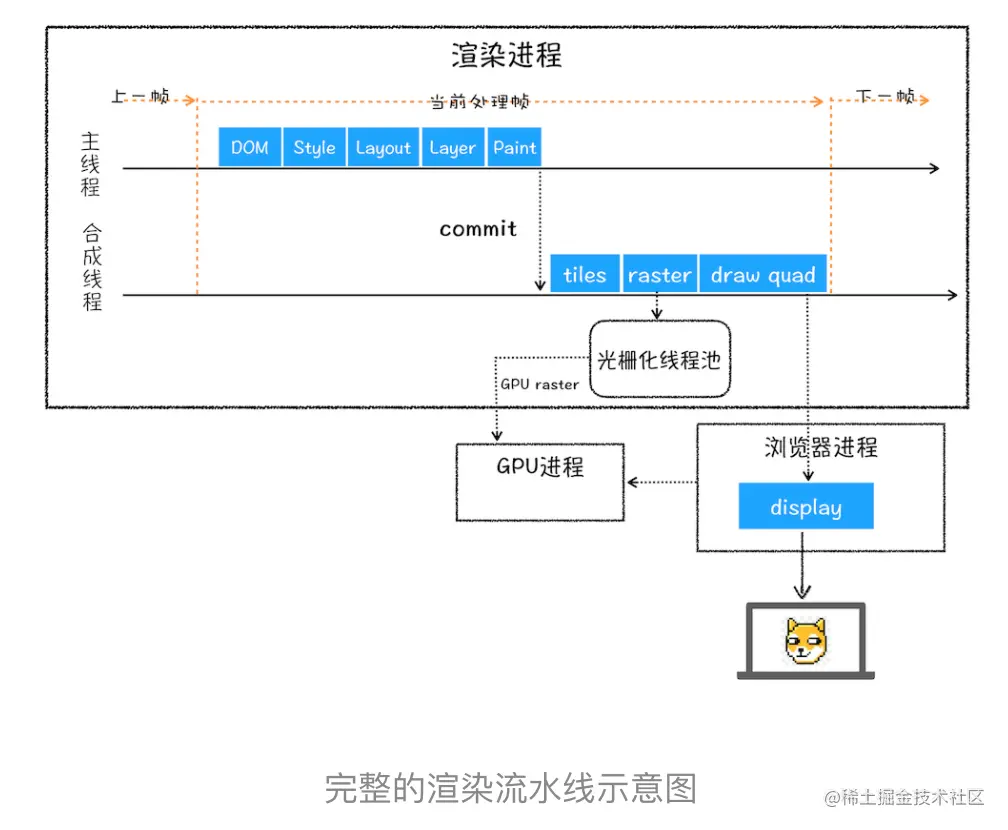 结合上图,一个完整的渲染进程大致可总结为如下:
结合上图,一个完整的渲染进程大致可总结为如下:
- 渲染进程将HTML内容转换为能够读懂的DOM树结构
- 渲染引擎将css样式表转化为浏览器可以理解的styleSheets,计算出DOM节点的样式
- 创建 布局树,并计算元素的布局信息。
- 对布局树进行分层,并生成分层树
- 为每个图层生成绘制列表,并将其提交到合成线程。
- 合成线程将图层分成图块,并在光栅化线程池中将图块转换成位图。
- 合成线程发送绘制图块命令 DrawQuad 给浏览器进程。
- 浏览器进程根据 DrawQuad消息生成页面,并显示到显示器上。
拓展:
重排:通过 JavaScript 或者 CSS 修改元素的几何位置属性,重排需要更新完整的渲染流水线,所以开销也是最大的。
重绘:重绘省去了布局和分层阶段,所以执行效率会比重排操作要高一些。
合成阶段:使用了 CSS 的 transform 来实现动画效果,这可以避开重排和重绘阶段,直接在非主线程上执行合成动画操作。这样的效率是最高的,因为是在非主线程上合成,并没有占用主线程的资源,另外也避开了布局和绘制两个子阶段,所以相对于重绘和重排,合成能大大提升绘制效率。
减少重排重绘, 方法很多:
- 使用 class 操作样式,而不是频繁操作 style
- 避免使用 table 布局
- 批量dom 操作,例如 createDocumentFragment,或者使用框架,例如 React
- Debounce (window resize,scroll) 事件
- 对 dom 属性的读写要分离
- will-change: transform 做优化